

Are you looking for What is Natural Language Processing?. If yes, then this blog is just for you. Here I will discuss What is Natural Language Processing, how to implement it in Python, and all other details. So, give your few minutes to this article in order to get all the details regarding What is Natural Language Processing?
Hello, & Welcome!
In this blog, I am gonna tell you-
What is Natural Language Processing (NLP)?
Before moving into more complex terms, let’s start with the basics.
So What do you understand by “Natural Language“?

Natural Language is nothing but the language which you and I use to communicate. In other words, Natural Language is a Human Language.
There are approximately 6500 languages are present all over the world. And we as human beings use these languages to communicate.
But computers and machines can’t understand these Natural Languages. Computers can only understand in 0 and 1 form.
And that’s why Natural Language Processing came into the picture. The aim of the Natural Language Processing is that computers and machines can also communicate like humans.
In short, Natural Language Processing is a part of Artificial Intelligence which deals with human language.
Now, you may be thinking What is the need of Natural Language Processing?
Right?
So, let’s see in the next section-
Why NLP is Important?
NLP is important because of mainly two reasons-
- NLP can handle large amount of Text data.
- Another one is NLP can structure highly unstructured data.
Now, let’s understand in detail-
As we know Data is growing very fast. On a daily basis huge amount of Data is generated.
The message you send to your friend, the post you upload on Facebook, your tweets, blogs published daily, and many more, all are Text data.
This data may contain various important information. As a Human Being its hard to read all text data and find out useful information. Right?
That’s why Natural Language Processing is used to process this huge text data.
But this data is not a Structured Data. All these data are Unstructured data.
Now, you may be thinking-
What is Structured and Unstructured Data?
So, let me simplify.
Suppose this is some Text Paragraph-
On July 16, 1969, the Apollo 11 spacecraft launched from the Kennedy Space Center in Florida. Its mission was to go where no human being had gone before—the moon! The crew consisted of Neil Armstrong, Michael Collins, and Buzz Aldrin. The spacecraft landed on the moon in the Sea of Tranquility, a basaltic flood plain, on July 20, 1969. The moonwalk took place the following day. On July 21, 1969, at precisely 10:56 EDT, Commander Neil Armstrong emerged from the Lunar Module and took his famous first step onto the moon’s surface. He declared, “That’s one small step for man, one giant leap for mankind.” It was a monumental moment in human history!
This kind of paragraph is unstructured data. Why?
Because this paragraph doesn’t have any row-column kind of structure. Here the text is written in a simple paragraph. There is no structure.
And almost all text data that is generated is unstructured data.
So, Natural Language Processing Structure this Unstructured data.
I hope now you understood the importance of Natural Language Processing.
Now, let’s see What are the applications of Natural Language Processing?
Applications of Natural Language Processing
NLP is used in various fields. Some most popular applications of NLP is-
- Sentiment Analysis- Sentiment Analysis is finding out the mood or feeling of a Text. Sentiment Analysis helps you to identify whether a text has a positive feeling or a negative feeling. In short, sentiment analysis recognizes different feelings from the text. You can perform sentiment analysis on Tweets, or on Facebook posts.
- ChatBot- When you have any query with any product, then you complain to the customer support. So when you send a message with your query, you get a reply within a few seconds. So, do you think, who replies to your query?. It’s a ChatBot. ChatBot understands your language via processing and then reply to your query. That’s all happening with the help of NLP.
- Speech Recognition- This is the most popular application of NLP. You are aware of Google’s assistant, Amazon Alexa, Apple’s Siri, and Cortana. So, the process behind all of these is because of NLP. When you give any voice commands to them, they process with your language and try to give the best answer to your question.
- Machine Translation- Many of us use Google Translation to translate from one language to another. And that is possible because of NLP.
- Some other applications of NLP include Spell Checking, Keyword searching, Information retrieval, and Advertisement Matching.
So, these are some most popular applications of NLP. I hope you understood.
Now, it’s time to move into some more technical part of NLP.
Components of Natural language Processing-
NLP is divided into two main Components. And that is-
- Natural Language Understanding
- Natural Language Generation.
You can understand the full processing of NLP with the help of this diagram-
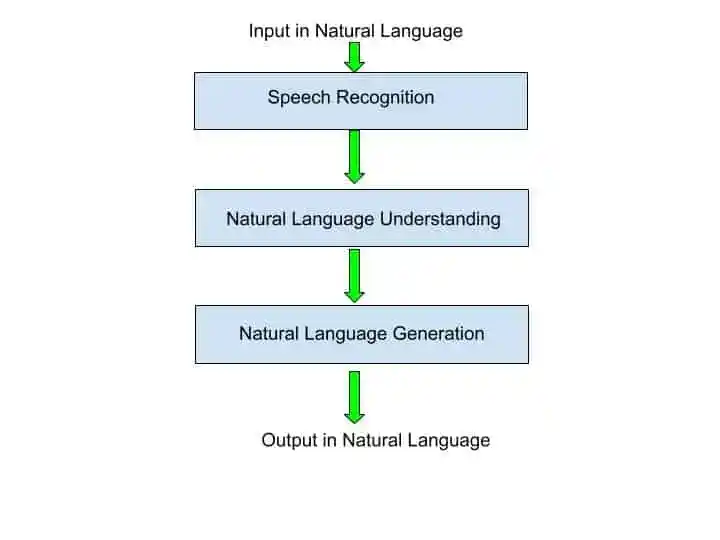
Now, let’s see what happens in each phase-
1. Natural Language Understanding
When you speak to the machine via voice, so the first step that happens inside speech recognition is understanding the language. As a human, it’s easy to understand the language of other people. But as a Machine, it’s difficult to understand the language.
There are various challenges that occur during the Natural Language Understanding Phase. Let’s see what are the challenges-
- Lexical Ambiguity
- Syntactical Ambiguity
- Semantic Ambiguity
1.1 Lexical Ambiguity
This ambiguity is a word-level ambiguity. That means one word may have different meanings. That’s why it’s difficult to understand the actual meaning of a word.
Suppose you said, ” I love Orange“.
So here “Orange” has two meanings, one is fruit , another one is color.
For machines, it’s difficult to understand the actual meaning of the word.
So, this type of word ambiguity comes under Lexical Ambiguity.
1.2 Syntactical Ambiguity
Here sentence structure-level ambiguity comes. The sentence structure which we pass may be ambiguous.
Suppose, in this sentence, “Old men and women were taken to a safe place.” It is not clear that both men and women are old or only men are old.
So, these types of sentences are ambiguous for machines to understand.
1.3 Semantic Ambiguity
In this ambiguity, understanding the meaning of a sentence comes. Suppose, in this sentence, ” The car hit the pole while it was moving.”
Here, it is not clear who is moving, a car or pole.
So, in this sentence meaning is not clear. And these types of ambiguity is very challenging for machines to understand.
So to overcome these challenges Stemming, lemmatization, and various other methods are used.
So, these are some most challenging issues that occurred in Natural Language Understanding. After the machine understands your language, the next step is to generate the answer according to your query.
Now, let’s see what is Natural Language Generation?
2. Natural Language Generation
After machine understands your language, they try to answer your query in natural language.
In Natural Language Generation, these are the steps used to generate the answer-
- Text Planning.
- Sentence Planning.
- Text Realization.
2.1 Text Planning
In that phase, relevant contents are retrieved from the knowledge base. That means machine to check which content is relevant to this query and collect these contents.
2.2 Sentence Planning
In that phase, the Natural Language Generation uses words, meaningful phrases, and sentiment-tone to form a sentence that is relevant to the query.
2.3 Text Realization
In that phase, Sentences are formed into a proper structure. That means it map sentence planning into sentence structure. And after that phase output is generated.
So, this is all about components of NLP. I hope you understood.
Now, let’s see what are the levels used in NLP?
Levels in Natural Language Processing
In NLP, these are the following levels-
- Lexical Analysis- In that level, all the sentences are divided into words and phrases. Many words are ambiguous like I discussed in the previous section. The word “Orange” has different meanings. So these types of ambiguities are solved in Lexical Analysis.
- Syntactic Analysis– In that level, sentences are formed into a proper structure. All the words are arranged in a proper structure.
- Semantic Analysis- This level tries to find the relevancy of the word for a given query. In short, here meaningfulness is checked for each word.
- Disclosure Integration- To find the core meaning of any sentence, we must know the before and after sentences of this sentence. So, Disclosure Integration finds out the before and after sentences for any sentence.
- Pragmatic Analysis- Pragmatic Analysis deals with the context of a sentence. That means it finds out the context because one sentence has various meanings in different situations. So to find out the actual intent or context of a sentence is done at that level.
So, this is all about the level in NLP.
Now, let’s see What are the preprocessing steps are used in NLP?
Data Preprocessing in Natural Language Processing
As I told you in the previous section that the data that is generated is Unstructured data. That means this is not in the proper structure.
NLP converts this unstructured data into structured data. So to convert it into a structured form, there are various preprocessing steps are performed.
These are some preprocessing steps are used in NLP.
- Tokenization.
- Stemming.
- Lemmatization.
- POS Tags,
- Named Entity Recognition.
- Chunking.
Now, let’s understand all of them one by one-
1. Tokenization

Tokenization is the first step in Data Preprocessing. Tokenization split the whole sentence into separate tokens.
Suppose, this is the sentence, “I am learning NLP”.
So, tokenization split this whole sentence into tokens something like that-
“I”, “am”, “learning”,”NLP”.
2. Stemming
Stemming normalize words into its base form or root form.
Suppose we have words- History and Historical
And if we apply stemming, so these words will be converted into- Histori.
One more example, suppose these are three similar words- Finally, Final, and Finalized.
So, after applying stemming. these words will be converted into- Fina.
“Fina” is the stem word. And Stemming is the process of reducing inflected words to their word stem.
3. Lemmatization
Lemmatization do the same job as Stemming do. But with a slight difference.
Lemmatization converts the words into meaningful words. These words are understandable by a human beings.
In stemming History and Historical are converted into Histori. This Histori doesn’t make any sense.
But, in Lemmatization, History, and Historical are converted into History. And History is a meaningful word.
Similarly, Finally, Final, and Finalized are converted into Final in Lemmatization.
I hope, now you understood the difference between Stemming and Lemmatization.
4. POS Tags
POS means part of speech. A word can have more than one Part of speech based on the context.
For example, This sentence, ” ‘Google’ something on the Internet.”
Here, “Google” is used as a verb although it’s a proper noun.
So, these are the some problems occurs during preprocessing of NLP.
5. Named Entity Recognition
To overcome the challenge of POS Tags, we have Named Entity Recognition.
So Named Entity Recognition is the process of detecting the name entities like a person name, a company name, locations, movies name, and quantities.
For example- “Microsoft’s CEO Satya Nadella went to New York.“
So, with the help of Named Entity Recognition, we can categorize as- Microsoft is an Organization, Satya Nadella is a person, and New York is a location.
6. Chunking
Once all these preprocessing steps are done, chunking is performed.
Chunking means taking up individual pieces of information and grouping them into bigger pieces.
Now you may be wondering how all these preprocessing happens in Machine.
Right?
So for this, there is NLTK Library in Python. NLTK is Natural Language Tool Kit Library.
Another question is Can We directly pass the Text to the Machine Learning Model?
Answer is No.
We convert Text into Bag of Words.
Now, you may be thinking What is Bag of Words?
So, don’t worry. I will explain you in the next section.
What is Bag of Words?
Suppose if we are working on Sentiment Analysis, so we can’t directly pass text data to the Model. We need to convert the text into some numerical form.
I will explain you Bag of Words with the help of an example.
Suppose these are the three sentences-
Sentence 1- “He is an intelligent boy”.
Sentence 2- “She is an intelligent girl”.
Sentence 3- “Boy and girl are intelligent.”
So, first of all, we perform some preprocessing as I discussed in the previous section. The preprocessing also involves lowering sentences. That means we need to convert all upper case characters into lower case.
These sentences are just for your understanding. In real time, there are thousands of words.
You also need to perform Stemming and Lemmatization. But in these sentences, there is no need to perform Stemming and Lemmatization. But in real data, you need to perform.
The next preprocessing step is Stop Words Removal. Stop words are not important for Sentiment Analysis.
For example in these three sentences- “He, She, is, an, and, are” are the stop words. So we can remove these stop words.
So, after applying lower case and stop words removal, we will get sentences like that-
Sentence 1- intelligent boy
Sentence 2- intelligent girl
Sentence 3- boy girl intelligent
Now we have three sentences, its time to create a Histogram.
Histogram counts the number of occurrences of any word. So in these three sentences, we count how many times “intelligent”, “boy”, and “girl” come.
| Words | Frequency |
| intelligent | 3 |
| boy | 2 |
| girl | 2 |
We need to sort this list into Descending order with respect to frequency.
Now its time to apply Bag of Words. In Bag of Words we convert the Histogram into vectors.
The words, “intelligent”, “boy”, and “girls” are our features.
Now, let’s see how to convert this histogram into vectors after applying Bag of Words.
| intelligent (f1) | boy (f2) | girl (f3) | Output | |
| Sentence 1 | 1 | 1 | 0 | |
| Sentence 2 | 1 | 0 | 1 | |
| Sentence 3 | 1 | 1 | 1 |
So, what is happening here?
In that Bag of Words table, we simply put 1 when the word is present in the sentence. And when the word is not present, we simply put 0. Very simple 🙂
For example, in sentence 1, intelligent and boy are present but the girl is not present that’s why it’s 1 1 0.
Similarly we put values for other sentences.
I hope you understood.
So, this f1, f2, and f3 are the independent variables. These independent variables are given to the Machine Learning model. And based on this f1, f2, and f3, the Machine Learning model will predict the output (the last column in Bag of Words Table).
Bag of Words have some disadvantages. Let’s see-
Disadvantages of Bag of Words
In that Bag of Words table, the sentence 1 has the word “intelligent” and “boy” both represents 1. That means we can’t know which word is more important for sentiment analysis. Because both have same value as 1.
In general, we know “intelligent” word is more important for sentiment analysis as compared to “boy” word. But in Bag of Words, both words have the same value and both words have equal weightage.
So, this is the major disadvantage of Bag of Words. Now the question comes What is the alternative of Bag of Words.
Alternative of Bag of Words
TFIDF is the alternative of Bag of Words. TFIDF means term frequency-inverse document frequency.
The next question is When to use Bag of Words and When to use TFIDF?
So, when you are doing Sentiment Analysis, you can use Bag of Words. But when you have huge amount of data, don’t use Bag of Words. In that case, TFIDF is the better option.
Now, you understood everything related to Bag of Words, its time to implement Sentiment Analysis or NLP in Python.
As we have converted the text into numeric or vector form. This numeric data is given to the machine learning model.
Now, let’ see how to implement NLP in Python.
How to implement NLP in Python?
In that example, I am using the Restaurant Review Data set. You can download the dataset from here.
Our aim is to find whether a Review is Positive or Negative.
So, the first step in Python is-
1. Import the Libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdAfter importing the libraries, the next step is-
Load the Dataset
dataset = pd.read_csv('Restaurant_Reviews.tsv', delimiter = '\t', quoting = 3)Here, we use quoting = 3, just to remove double quotes in the text.
Now the next step is cleaning the text-
Cleaning the Text
Cleaning involves converting into lower case, removal of stop words, and stemming.
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, 1000):
review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review = [ps.stem(word) for word in review if not word in set(stopwords.words('english'))]
review = ' '.join(review)
corpus.append(review)After applying cleaning on text data, we will get corpus something like that-
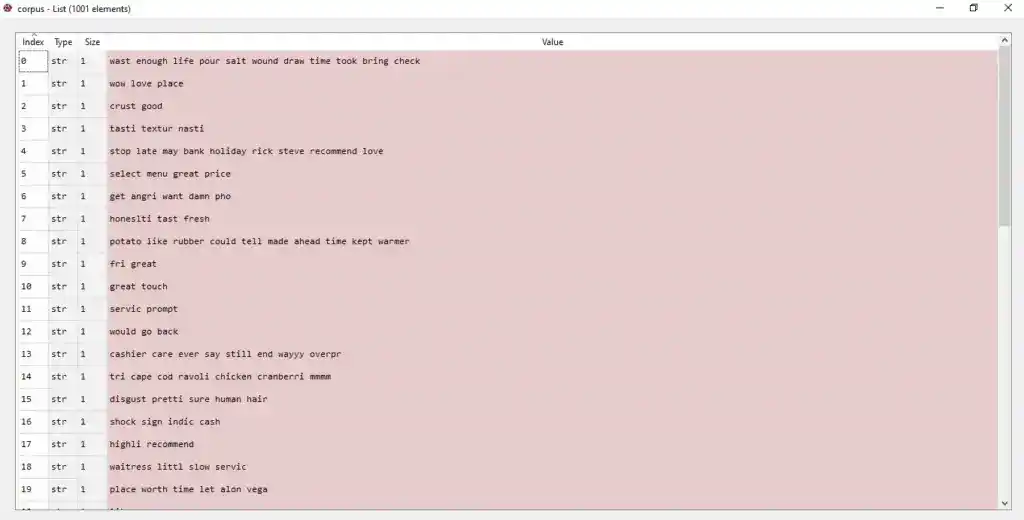
Now, the next step is converting this text data into numeric form. So for that, we use Bag of Words.
Creating a Bag of Words
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features = 1500)
X = cv.fit_transform(corpus).toarray()
y = dataset.iloc[:, 1].valuesHere, x is the independent variables whereas y is the dependent variables.
Now the next step is-
Split the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)Now we split the dataset into Training set data and Test set data.
The next step is-
Fit Machine Learning Algorithm to the Training set
Here, I am using the Naive Bayes Classification algorithm. You can use any other Machine Learning Algorithm and find out the accuracy.
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)After training the data, the next step is-
Predict the Test set Result
y_pred = classifier.predict(X_test)After running this line of code, you will get prediction results.
Now its time to calculate the accuracy of our model with the help of confusion matrix.
Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
print (cm)
accuracy_score=(y_test,y_pred)So, after running these lines of code, we will get confusion metrix and accuracy.
In that case, I will get Confusion Matrix-
55 42
12 91
And Accuracy as – 73%.
You can apply any other Classification algorithm and check the accuracy.
I hope you understood everything related to NLP.
Now, its time to wrap up.
Conclusion
In this article, you learned everything related to the Natural Language Processing.
Specifically, you learned-
- What is the Natural Language Processing?, Applications of Natural Language Processing, and Components of Natural language Processing.
- Levels in Natural Language Processing, Data Preprocessing in Natural Language Processing,
- What is Bag of Words?
- How to implement NLP in Python?
I tried to make this article simple and easy for you. But still, if you have any doubt, feel free to ask me in the comment section. I will do my best to clear your doubt.
Enjoy Machine Learning
All the Best!
Explore more about Artificial Intelligence.
Thank YOU!
Though of the Day…
‘ Anyone who stops learning is old, whether at twenty or eighty. Anyone who keeps learning stays young.
– Henry Ford

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.