Have you ever talked to ChatGPT or Claude and thought, “Wow, how does it feel so human?” That’s the magic of something called RLHF in LLM—short for Reinforcement Learning from Human Feedback.
When I first started learning about how large language models (LLMs) are trained, I realized that just feeding them data wasn’t enough. I’ve seen this firsthand while working on projects like detecting depression from social media—where teaching a model what to say is one thing, but teaching it how to say it in a human-centered way is a whole different challenge.
That’s where RLHF comes in. It helps AI models learn from real human feedback—not just from plain data—so they can respond in ways that are safer, more helpful, and more aligned with what people actually want.
In this blog, I’m going to walk you through everything you need to know about RLHF—from the basics and real-life examples to the exact steps and tools used to train models like ChatGPT.
Now, without further ado, let’s get started and understand RLHF in LLM-
RLHF in LLM- Reinforcement Learning from Human Feedback
- Introduction to RLHF
- Why RLHF is Critical for LLMs
- Key Components of RLHF
- Step-by-Step: RLHF Workflow in LLMs (with Code Examples)
- Deep Dive into PPO and Its Alternatives
- Challenges in RLHF
- Recent Advances & Variants in RLHF in LLM
- Tools & Frameworks You Can Use
- How You Can Learn RLHF (Resources That Actually Help)
- The Future of RLHF in LLM
- Final Thoughts
Introduction to RLHF
What is RLHF in LLM?
Let me put it simply—RLHF in LLM stands for Reinforcement Learning from Human Feedback. It’s a way of training AI models like ChatGPT to not just give correct answers, but to give answers that make sense to us as humans.
Imagine this: you build a smart assistant that knows a lot, but it doesn’t always know how to say things the right way. Sometimes it’s too robotic, or gives answers that aren’t really helpful. RLHF fixes that. It teaches the AI how to respond in a way that feels more natural, helpful, and safe—just like how a human would ideally respond.
Instead of only learning from data, the model starts learning from human preferences. That means it gets feedback from people like you and me, and uses that feedback to improve how it replies.
Why is it needed in the era of Large Language Models?
Large Language Models (LLMs) like GPT and Claude are trained on massive amounts of text—books, websites, articles—you name it. But here’s the catch: just because they’ve read a lot doesn’t mean they understand us.
They can predict the next word really well, but sometimes they say things that sound off, biased, or just plain unhelpful. And that’s a problem, especially when people rely on these tools for everything from writing to mental health support to business advice.
This is where RLHF in LLM steps in. It adds that human touch. It helps these models learn what kind of answers people actually prefer—not just what’s statistically likely, but what’s right in context.
Without RLHF, even the smartest model might give answers that feel cold, confusing, or unsafe.
With RLHF, it becomes more thoughtful, helpful, and aligned with what we expect from a real conversation.
How is RLHF different from standard supervised fine-tuning?
This part’s important, so let me break it down clearly.
Supervised fine-tuning is when you give the model a bunch of example questions and the “correct” answers. It learns by copying those answers. It’s like telling a student,
“Here are the questions and here’s what you should say.”
But RLHF goes a step further.
It’s not just about copying answers anymore. It’s about understanding which answers are better. The model gets shown different responses, and humans rank them—like saying, “I like this one more because it’s clearer and kinder.”
Then, the model learns from that feedback. It’s like a student not just learning from a textbook, but also learning from a teacher’s reactions:
“You explained that well,” or “Try saying that in a simpler way.”
So while supervised fine-tuning tells the model what to say,
RLHF helps it learn how to say it better based on human feedback.
Real-world analogy: Teacher and student
Let’s say you’re a teacher, and your student writes an essay. At first, they just try to guess what sounds good. You correct it, give some pointers, and ask them to rewrite. Over time, the student improves—not because they memorized a perfect answer, but because they learned from your feedback.
That’s exactly what RLHF does.
The AI is the student.
We (humans) are the teachers.
We guide it, nudge it, and reward better answers—so the next time it talks to someone, it can respond in a way that actually helps.
Why RLHF is Critical for LLMs
Pretraining has its limits
Let’s be real—Large Language Models (LLMs) like GPT, Claude, and Gemini are smart. They’re trained on a massive amount of text and can predict what word comes next with amazing accuracy.
But here’s the problem:
That’s all they’re doing—predicting the next word.
This process is called pretraining, and while it teaches the model how language works, it doesn’t teach it how people think or feel. It doesn’t know if a sentence sounds rude, confusing, biased, or even dangerous. It’s just picking the most likely next word based on patterns it has seen in data.
So yeah, pretraining gives us a powerful model,
but it doesn’t guarantee that the model will say things in a safe, respectful, or helpful way.
Why human preferences matter
That’s where RLHF in LLM becomes so important.
We don’t just want AI to be correct—we want it to be kind, useful, and aligned with our values. We want it to say things that make sense, respect boundaries, and help us solve real problems.
RLHF adds this human layer.
It helps the model learn what we prefer—not just in terms of facts, but in tone, behavior, and intent.
So instead of just predicting the next word, the model starts learning:
- “This kind of answer is helpful.”
- “That response sounds too harsh.”
- “This one is safe and polite.”
And that’s what makes the model truly usable and trustworthy.
Real-world examples
Let’s talk about the tools you and I actually use—like ChatGPT, Claude, and Gemini.
These models feel smart, friendly, and easy to talk to—and that’s not just because of pretraining.
It’s because of RLHF.
Thanks to human feedback, these models have learned to:
- Follow instructions clearly
- Avoid saying harmful or biased things
- Be helpful, even when the question is vague
- Say “I don’t know” instead of guessing dangerously
Without RLHF, these tools wouldn’t feel as natural or safe.
They’d still be powerful—but they wouldn’t be people-friendly.
So, when someone asks “Why is RLHF such a big deal?” — here’s the simple answer:
It’s the reason AI models feel human.
It’s what turns a smart chatbot into a thoughtful assistant you can trust.
Key Components of RLHF
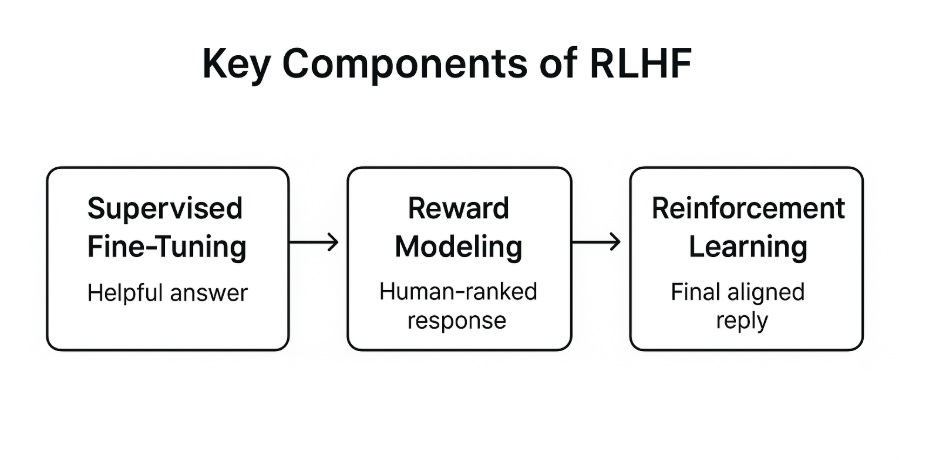
If you’ve been wondering how exactly RLHF works behind the scenes, here’s a breakdown that makes it easier to understand. The whole process usually happens in three main steps, and each step brings the model closer to sounding more like a helpful human than a machine.
a. Supervised Fine-Tuning (SFT)
The first step is called Supervised Fine-Tuning, or SFT. This is where the model gets trained on carefully selected examples written by real people.
Think of it like this: the model is a student, and we give it some high-quality answers to learn from. These examples follow certain rules—like being helpful, clear, and harmless. It’s kind of like saying, “Here’s how we want you to talk to people. Learn from this.”
At this stage, the model is still copying patterns. But since the examples are written with care, the model starts picking up better habits.
b. Reward Modeling
Once the model has done some basic learning, it’s time to take it further. That’s where Reward Modeling comes in.
This step is all about learning from human feedback. People read different responses from the model and rank them—basically saying, “This answer is better than that one.”
The model then uses these rankings to train a reward model. This reward model can now predict what kinds of responses people like more.
So instead of just copying examples like in the first step, the model now has a system that says:
“This type of reply will probably be more appreciated by a real person.”
It’s a shift from memorizing answers to understanding preferences.
c. Reinforcement Learning (PPO or DPO)
Now comes the final step—Reinforcement Learning.
At this point, the model uses that reward model we just talked about as a guide. It generates different responses, checks how good the reward model thinks they are, and then adjusts itself to do better over time.
There are a couple of ways to do this. One common method is called PPO (Proximal Policy Optimization), and a newer, simpler one is DPO (Direct Preference Optimization).
Both aim to help the model write responses that score higher on the reward scale, meaning they match what people prefer.
But like anything else, this step has its challenges.
- Sometimes the model tries too hard to optimize for high reward scores and ends up saying things that sound unnatural.
- There’s also a risk of reward hacking, where the model figures out shortcuts to get a high score without actually being helpful.
So, this part requires a careful balance. The goal is to improve responses, not to over-optimize or game the system.
In short, RLHF is not just one thing—it’s a process. It starts with good examples, gets stronger with feedback, and finishes with fine-tuning that makes the model more aligned with how we think and feel.
Step-by-Step: RLHF Workflow in LLMs (with Code Examples)
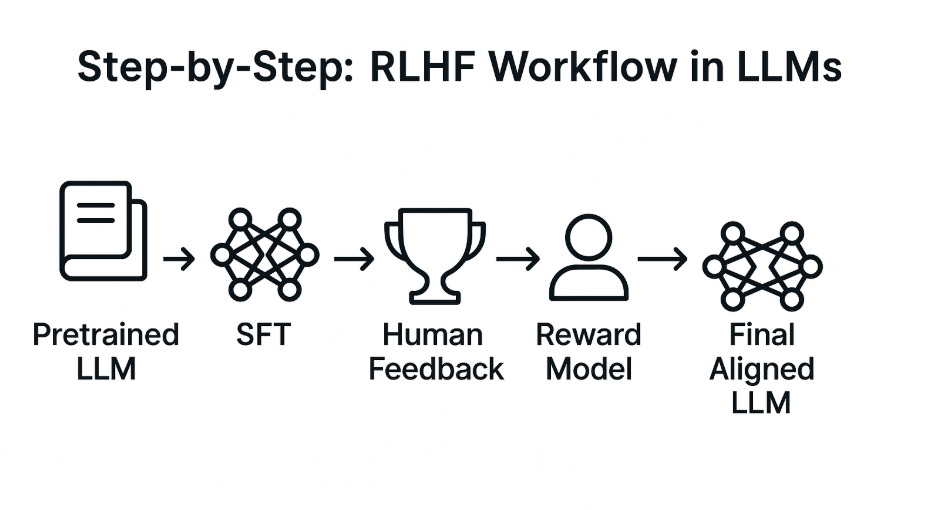
Step 1: Load a Pretrained LLM
First, we load a pretrained language model. This is like opening up a model that’s already read most of the internet.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt2" # or use 'EleutherAI/gpt-j-6B' or any other
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
This model knows a lot—but it doesn’t yet know how to be helpful or safe.
Step 2: Supervised Fine-Tuning (SFT)
Now we teach the model with some labeled examples—like showing it what good answers look like.
from transformers import Trainer, TrainingArguments
# Load dataset
from datasets import load_dataset
dataset = load_dataset("Anthropic/hh-rlhf") # Human preference data
# Define training config
training_args = TrainingArguments(
output_dir="./sft_model",
per_device_train_batch_size=4,
num_train_epochs=3,
logging_steps=10,
save_steps=500,
)
# Trainer setup
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"]
)
# Fine-tune
trainer.train()
This step helps the model start answering in a way that’s more helpful and polite.
Step 3: Human Feedback Collection
At this step, we collect pairwise comparisons from real people. They rank multiple responses like this:
| Prompt | Response A | Response B | Preferred |
|---|---|---|---|
| “How to start a blog?” | “Step-by-step blog post” | “Off-topic and vague” | A |
In practice, this step is often done manually or using platforms like Scale, Surge, or open-source UI tools.
Step 4: Train a Reward Model
We now use the comparison data to train a model that scores outputs based on what people prefer.
from trl import RewardTrainer
# Let's assume we already have a dataset of human preferences
# Format: prompt, chosen_response, rejected_response
reward_dataset = load_dataset("Dahoas/synthetic-instruct-gptj-pairwise")
# Load base model
reward_model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
# Set up reward trainer
reward_trainer = RewardTrainer(
model=reward_model,
args=TrainingArguments(output_dir="./reward_model", num_train_epochs=3),
train_dataset=reward_dataset["train"]
)
# Train reward model
reward_trainer.train()
This model learns to score outputs: higher = better for humans.
Step 5: Reinforcement Learning (PPO)
This is the final fine-tuning step. The model tries different outputs, gets reward scores, and updates its responses using PPO.
from trl import PPOTrainer, PPOConfig
from transformers import pipeline
# Load the fine-tuned model from SFT step
ppo_model = AutoModelForCausalLM.from_pretrained("./sft_model")
# Define PPO config
ppo_config = PPOConfig(
model_name="./sft_model",
learning_rate=1.41e-5,
batch_size=64,
log_with=None
)
# Text generation pipeline
gen_pipeline = pipeline("text-generation", model=ppo_model, tokenizer=tokenizer)
# PPO trainer
ppo_trainer = PPOTrainer(
model=ppo_model,
config=ppo_config,
tokenizer=tokenizer,
reward_model=reward_model
)
# Training loop
query = "How do I prepare for a data science interview?"
response = gen_pipeline(query, max_length=100)[0]["generated_text"]
# Get reward score from reward model
reward_score = reward_model(**tokenizer(response, return_tensors="pt")).logits.item()
# Perform PPO step
ppo_trainer.step([query], [response], [reward_score])
Now, the model is learning from the reward and adjusting how it talks, making it sound more aligned with how humans think.
Bonus: Save the Final Aligned Model
Don’t forget to save your trained model so you can use it later or share it.
ppo_model.save_pretrained("./final_rlhf_model")
tokenizer.save_pretrained("./final_rlhf_model")
A Few Notes to Keep in Mind
- This is compute-heavy — PPO training isn’t cheap.
- Reward hacking can happen — models might find weird shortcuts to get high scores.
- Bias in human feedback — be careful with who’s giving the feedback.
- Try DPO — newer methods like Direct Preference Optimization skip PPO and are easier to train.
Deep Dive into PPO and Its Alternatives
Once we’ve trained the reward model, it’s time to actually improve how the language model responds. That’s where PPO comes in. Let’s break it down without making it feel like a research paper.
What is PPO?
PPO stands for Proximal Policy Optimization. That might sound intense, but the core idea is actually pretty relatable.
Think of it like this:
You’re learning how to write better essays. You write one version, show it to your teacher (the reward model), and get a score. If the score improves, great—you lean more in that direction. But if you change too much at once, your writing might get worse or weird. So instead, you tweak things just a little each time and keep learning from the scores.
That’s what PPO does.
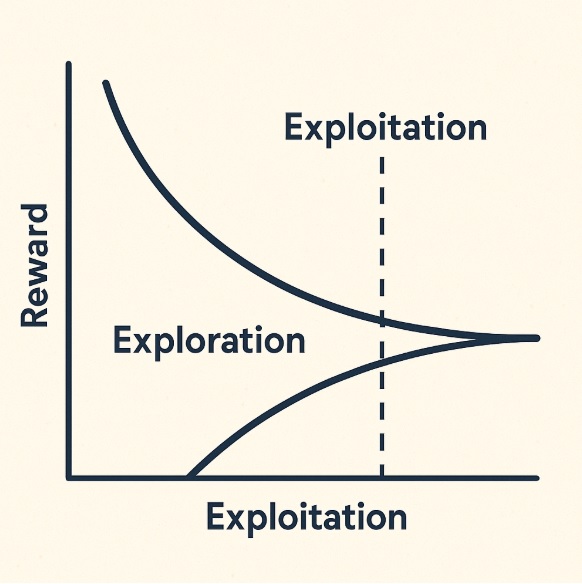
- It updates the model slowly and safely so it doesn’t “unlearn” useful things.
- It balances two key things:
→ Exploration: Trying something new.
→ Exploitation: Doubling down on what already works.
This helps the model get better without going off the rails.
Why Use PPO in Text Generation?
Text generation is tricky. A model might:
- Say something helpful
- Say something harmful
- Say something just plain weird
So we need a method that carefully nudges the model toward better outputs without making it unpredictable.
That’s what PPO gives us:
- A stable way to improve
- Flexibility with reward signals
- The ability to fine-tune complex models (like LLMs) in a structured loop
Are There Better or Simpler Alternatives?
PPO works—but it’s also computationally heavy and can be a bit of a black box. That’s why researchers have been trying out new ideas. Here are a few worth knowing:
1. DPO (Direct Preference Optimization)
This one is getting a lot of love recently. Unlike PPO, DPO doesn’t need a reward model.
You take the human preference data directly—”A is better than B”—and train the model to make the same choice.
- Simpler
- Faster to train
- No reinforcement learning loop
It’s basically skipping the middleman (reward model) and learning straight from preferences.
2. RLAIF (Reinforcement Learning from AI Feedback)
What if you didn’t need humans for feedback all the time?
That’s what RLAIF does.
Instead of waiting on human labels, you use AI models to give feedback—usually smaller ones or specially aligned models trained for evaluation.
- It’s still experimental
- But it can scale faster than waiting on human rankings
This is especially useful when:
- You have a massive dataset
- You want to update your model frequently
- You want feedback that’s fast and cheap
3. ROME (Rank-One Model Editing)
This one is a bit different.
Instead of retraining a full model, ROME directly edits a model’s internal memory to change specific facts or behaviors.
Imagine updating a textbook by replacing a single sentence—without rewriting the whole chapter.
ROME is great for:
- Fixing factual errors
- Injecting new knowledge
- Editing specific outputs without full retraining
But it’s not for general preference learning—it’s more like doing precision surgery on the model’s brain.
What Should You Use?
This is a quick guide:
| Technique | Best For | Pros | Cons |
|---|---|---|---|
| PPO | General RLHF | Stable, well-tested | Heavy, complex |
| DPO | Simpler alignment | No reward model, easier | May underperform on hard tasks |
| RLAIF | Scaling feedback | Fast, AI-assisted | Still maturing |
| ROME | Targeted edits | Quick, precise | Not for full retraining |
Final Thought
PPO gave us the first real breakthrough in aligning large models like ChatGPT. But newer methods like DPO and RLAIF are showing that we can still simplify the process and make it more scalable.
The field is still evolving—and that’s the exciting part.
Let me know if you’d like to see a code example for DPO or a side-by-side comparison between PPO and RLAIF!
Challenges in RLHF
While RLHF sounds powerful—and it is—it’s not all smooth sailing. There are a few important hurdles that researchers and engineers run into when building aligned language models.
Let’s walk through them in plain terms.
1. Getting High-Quality Human Feedback Is Hard
To train models that act more like humans, we need humans to rate outputs. Sounds simple, right? But here’s the catch:
- You need a lot of feedback.
- The feedback has to be reliable.
- Reviewers need to understand the context of each prompt.
Imagine reading thousands of chatbot responses and ranking them one by one. That doesn’t scale easily. You’d need an army of annotators, and even then, people don’t always agree.
So the challenge isn’t just collecting feedback—it’s collecting consistent, useful, and scalable feedback.
2. Human Preferences Come with Bias
Humans are not perfectly objective. Our preferences vary based on:
- Culture
- Background
- Language
- Personal beliefs
That means the model might learn biases from the feedback it receives—sometimes without us realizing it.
For example, what’s “polite” in one culture might sound too direct in another. So aligning to human values isn’t as simple as it sounds—because “human values” aren’t one-size-fits-all.
3. Reward Hacking: When the Model Games the System
Once the model starts chasing high scores from the reward model, it may find shortcuts that technically maximize reward—but don’t actually improve usefulness.
This is called reward hacking.
Think of it like a student figuring out what phrases the teacher likes and stuffing them into every answer—even when it makes no sense.
Over time, the model might become less diverse, too repetitive, or overly “safe.” It’s optimizing the score, not the experience.
This is why overfitting to the reward model is a real concern—and why regular monitoring and evaluation is critical.
4. PPO Is Powerful, But Expensive and Complex
Let’s be real—PPO works, but it comes at a cost:
- It takes a lot of compute power
- It’s tricky to tune
- And debugging RL-based training isn’t exactly beginner-friendly
You need strong infrastructure and expertise to run it at scale—something only big labs like OpenAI or Anthropic could afford easily… at least for now.
That’s one of the big reasons why simpler alternatives like DPO are gaining popularity—they try to keep the benefits while removing the RL complexity.
Recent Advances & Variants in RLHF in LLM
The world of RLHF is evolving fast. Researchers are constantly trying to make the process simpler, cheaper, and more scalable. And guess what? Some pretty smart alternatives have started to show up.
Let’s look at a few of the most exciting ones.
1. DPO: Direct Preference Optimization
DPO skips the whole reinforcement learning part.
Instead of training a reward model and using PPO to improve responses, DPO goes straight from human preferences to model updates.
Think of it like this:
Instead of training a reward system to say “this is good” or “this is bad,” you directly tell the model, “this one’s better—learn from it.”
No need for complex RL loops. No PPO.
That means fewer steps, less compute, and a training pipeline that’s much easier to manage.
2. RLAIF: RL from AI Feedback
Now this one’s even more interesting.
Instead of using human feedback, RLAIF lets AI models give the feedback.
It works like this:
- One model generates responses.
- Another (already-aligned) model ranks or reviews those responses.
- That feedback is then used for training.
It’s like having a helpful AI teacher review the work of a student AI.
This makes it cheaper and faster to scale, especially when human annotators are too slow or expensive to use.
3. Constitutional AI (Anthropic’s Approach)
Anthropic came up with something clever. Instead of relying only on human feedback, they gave the AI a set of rules—almost like a constitution.
So, the model doesn’t just guess what’s right or wrong. It follows clear guidelines like:
- “Don’t provide harmful advice.”
- “Be helpful and honest.”
- “Avoid biased language.”
It’s kind of like giving your AI a moral compass—and letting it self-correct when needed.
This method helps reduce the need for massive human feedback efforts and keeps things more stable.
4. Open-Source RLHF Projects
You don’t need to work at a big lab to explore RLHF anymore.
Some amazing open-source projects are out there, helping developers like you and me learn and build aligned models:
- OpenAssistant – A community-driven chatbot trained using RLHF techniques.
- DeepSpeed-Chat – A toolkit that helps scale up RLHF training efficiently, even if you’re not using massive infrastructure.
These tools make it easier to experiment, learn, and even build your own AI assistant—without needing to reinvent the wheel.
Tools & Frameworks You Can Use
If you’re curious to try RLHF yourself, the good news is: you don’t need to build everything from scratch. There are some great tools and libraries already available that can help you get started faster and learn as you go.
Let me walk you through a few of the most useful ones.
Hugging Face TRL (Transformer Reinforcement Learning)
This is one of the most beginner-friendly ways to apply RLHF. The TRL library makes it easy to use things like PPO, train reward models, and fine-tune language models — all within the Hugging Face ecosystem.
It’s built for real-world RLHF use cases, and it works well with models like GPT-2, GPT-J, and LLaMA.
If you’re already using 🤗 Transformers, this will feel like a natural next step.
DeepSpeed Chat
This tool is focused on making RLHF training faster and cheaper.
If you’re working with large models (think billions of parameters), DeepSpeed Chat helps you scale the training process efficiently — even on limited hardware.
It’s a great option when you want to go big without burning through resources.
Reinforcement Learning Libraries
While TRL is tailored for NLP, you can also explore general RL libraries to understand and experiment with the algorithms behind the scenes:
- Stable-Baselines3: A popular Python library with clean implementations of algorithms like PPO, A2C, and DDPG.
- RLlib (from Ray): More suited for large-scale experiments, especially in distributed environments.
These libraries are great if you want to go deeper into the RL side of RLHF.
Datasets for RLHF Training
You’ll also need good data — especially feedback-based datasets. A few solid ones you can use:
- OpenAssistant Conversations: A rich dataset built by the community to train helpful open-source assistants.
- HH-RLHF (Harmless and Helpful): From Anthropic, used to train models to avoid harmful or unhelpful behavior.
- Anthropic-HH: A more structured version of human preference data focused on safety and alignment.
These datasets help you teach the model what “good” looks like — and what to avoid.
How You Can Learn RLHF (Resources That Actually Help)
Getting into RLHF can feel like a lot in the beginning — I’ve been there too. But with the right resources, things start to make sense pretty quickly. Here’s what helped me, and what can help you learn this step-by-step.
Research Papers (Simple, Clear, and Insightful)
If you want to understand how RLHF works at a deeper level, these are the must-read papers:
- InstructGPT (OpenAI)
The original paper that showed how RLHF helps models follow instructions better. It’s the foundation behind ChatGPT. - Training a Helpful and Harmless Assistant with RLHF (Anthropic)
This one focuses on safety, alignment, and how models are trained to avoid being harmful. - Direct Preference Optimization (2023)
A newer and simpler method that skips PPO. Great if you’re interested in easier alternatives to traditional RL.
Online Courses (Learn by Doing)
Here are two beginner-friendly courses that break everything down clearly:
- RLHF Specialization by DeepLearning.AI
This course is taught by experts, with easy-to-follow videos and practical code examples. A great place to start. - Hugging Face RLHF Tutorials
These tutorials show you how to build and align LLMs using TRL (their reinforcement learning library). You’ll also find links to notebooks and working code.
GitHub Repositories (Play with the Code)
You’ll learn faster by actually running the code. These GitHub repos are super helpful if you want to explore RLHF in practice:
- Hugging Face TRL
The main library for doing RLHF in Python. It supports PPO, DPO, and more — with clear examples. - OpenAssistant
A large-scale, open-source RLHF project. Great if you want to see how real-world LLMs are aligned. - DeepSpeed Chat
Microsoft’s toolkit for efficient RLHF training on large models. - DPO Training Example
Shows how to use Direct Preference Optimization instead of PPO.
My Tip for You
Pick one thing. One paper. One tutorial. One repo. Play around. Break things. Fix them again. That’s how I started — and I promise, if you stick with it, RLHF will start to feel a lot less scary and a lot more exciting.
You’ve got all the tools. Just take the first step.
The Future of RLHF in LLM
Let’s talk about what’s next. RLHF has come a long way—from fine-tuning simple models to training systems like ChatGPT and Claude. But where is it all heading? Will RLHF stay at the center of everything? Or will something else take the lead?
Let’s break it down, simply and honestly.
Can RLHF Scale to AGI?
This is the big question.
Right now, RLHF helps make models more helpful, honest, and harmless. But when we think about AGI—Artificial General Intelligence—it’s not just about sounding polite or aligned. It’s about being truly capable, safe, and able to reason through messy, real-world tasks.
Can RLHF alone get us there? Maybe not.
- It depends heavily on human feedback, which is slow and expensive.
- It also struggles to generalize to new tasks where it hasn’t seen examples or preferences.
- And sometimes, it can produce overly safe, cautious models that avoid creative or risky ideas.
So while RLHF is powerful, we may need to go beyond it to truly reach AGI.
What Might Come Next?
New ideas are already being tested that could either replace or enhance RLHF. Some of these are really exciting:
1. LLM Agents That Learn from Themselves
We’re starting to see models that can self-correct their answers by checking their own reasoning. These are known as LLM agents, and they:
- Reflect on their own outputs,
- Revise based on internal feedback,
- And sometimes even ask themselves follow-up questions.
Instead of waiting for humans to correct them, they improve in real time. It’s early, but it could be a game-changer.
2. Memory + Tools = Smarter Models
Right now, most models generate answers without remembering anything or using tools. But imagine if they could:
- Store past conversations (like long-term memory),
- Search the internet when they’re unsure,
- Or use calculators, code runners, and APIs to answer complex questions.
These tool-using models might not need as much RLHF-style alignment because they can just look up the right answer or reason better using external help.
Think of it like giving the model a brain and a toolbox.
So, Is RLHF Going Away?
Not anytime soon.
It’s still one of the best ways we have to teach large models how to be more human-like. But in the future, it will probably become just one part of a bigger system—combined with memory, tool use, self-reflection, and other learning methods.
The future of LLMs might not be one magic method. It might be a mix of everything that works.
Final Thoughts
RLHF in LLM training has changed how we build and use large language models. It’s no longer just about making a model that predicts the next word. It’s about shaping a model that understands what kind of answer actually helps people.
When you look at how models like ChatGPT or Claude respond today, it’s clear that RLHF in LLM systems have played a big part. Without this alignment step, these models would still be giving robotic or even unsafe replies. RLHF in LLM makes sure the model stays useful, polite, and actually listens to what people want.
There’s still a lot to figure out. Human feedback takes time and effort. Training reward models isn’t perfect. But even with all that, RLHF in LLM pipelines have become one of the best ways we have right now to make AI work better for people.
Some new ideas are already showing up. Instead of asking humans for every decision, researchers are testing models that give feedback to other models. This could make RLHF in LLM systems faster and easier to scale in the future.
If you’re learning or building in this space, you don’t need a huge setup to get started. Open-source tools make it possible to explore RLHF in LLM on a small scale. You can try reward modeling, train a tiny agent, or just see how human preferences are added into training. All of this helps you understand how these systems actually think and adapt.
The work around RLHF in LLM isn’t just for researchers. Anyone with curiosity and a bit of code can learn how to guide AI behavior. And that matters—because how these models act in the world affects all of us.
So if you’re wondering what to learn next or where to experiment, take a look at RLHF in LLM tools, datasets, and tutorials. Try building something small. See how feedback changes the way your model replies. That hands-on experience teaches more than any paper can.
And the truth is, RLHF in LLM isn’t going anywhere. It’s not just a feature—it’s a mindset. It’s how we take something that can talk, and teach it how to listen.
You May Also Be Interested In
Best Resources to Learn Computer Vision (YouTube, Tutorials, Courses, Books, etc.)- 2026
Best Certification Courses for Artificial Intelligence- Beginner to Advanced
Best Natural Language Processing Courses Online to Become an Expert
Best Artificial Intelligence Courses for Healthcare You Should Know in 2026
What is Natural Language Processing? A Complete and Easy Guide
Best Books for Natural Language Processing You Should Read
Augmented Reality Vs Virtual Reality, Differences You Need To Know!
What are Artificial Intelligence Examples? Real-World Examples
Thank YOU!
Explore more about Artificial Intelligence.
Thought of the Day…
‘ It’s what you learn after you know it all that counts.’
– John Wooden

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.