
Are you looking for a complete guide on Hierarchical Clustering in Python?. If yes, then you are in the right place. Here I will discuss all details related to Hierarchical Clustering, and how to implement Hierarchical Clustering in Python. So, give your few minutes to this article in order to get all the details regarding the Hierarchical Clustering.
Hello, & Welcome!
In this blog, I am gonna tell you-
Hierarchical Clustering in Python
Before moving into Hierarchical Clustering, You should have a brief idea about Clustering in Machine Learning.
That’s why Let’s start with Clustering and then we will move into Hierarchical Clustering.
What is Clustering?
Clustering is nothing but different groups. Items in one group are similar to each other. And Items in different groups are dissimilar with each other.
In Machine Learning, clustering is used to divide data items into separate clusters. Similar items are put into one cluster.
In that image, Cluster 1 contains all red items which are similar to each other. And in cluster 2 all green items are present.
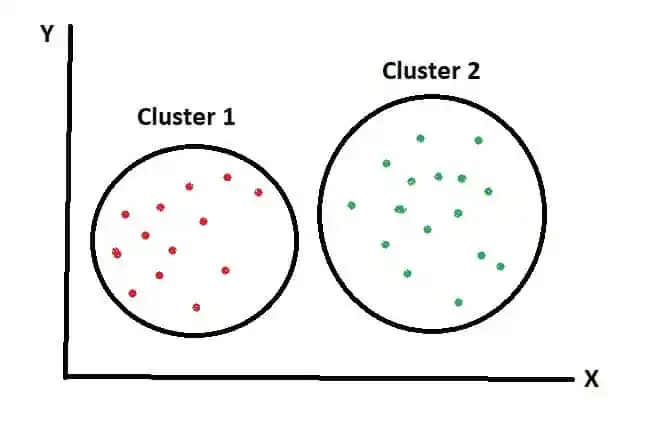
Clustering is known as Unsupervised Learning.
Now you may be wondering where clustering is used?
You can see the clustering in the Supermarket. In the supermarket, all similar items are put in one place. For example, one variety of Mangoes are put in one place, where other varieties of Mangoes are placed in another place.
Now let’s see Different Types of Clustering-
Types of Clustering Algorithm in Machine Learning
Clustering is of 3 Types-
- Exclusive Clustering.
- Overlapping Clustering.
- Hierarchical Clustering.
1. Exclusive Clustering
It is known as Hard Clustering. That means data items exclusively belong to one cluster. Two clusters are totally different from each other. As you saw in the previous image. Where Red Items are totally different from Green Items.
Example of Exclusive Clustering is K Means Clustering.
2. Overlapping Clustering
Overlapping clustering is a soft cluster. That means data items may belong to more than one cluster.
As you can see in that image, two clusters are overlapping. Because data points are not belonging to one cluster.
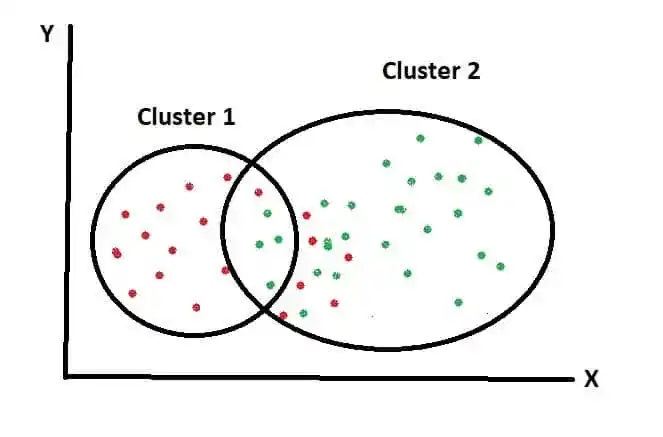
An example of Overlapping Clustering is Fuzzy or C Means Clustering.
3. Hierarchical clustering
Hierarchical Clustering groups similar objects into one cluster. The final cluster in the Hierarchical cluster combines all clusters into one cluster.
An example of Hierarchical clustering is Dendrogram.
Now you gained brief knowledge about Clustering and its types. Our main focus is Hierarchical Clustering, so let’s move into it.
What is Hierarchical Clustering?
Hierarchical clustering separate the data points into clusters. Similar Clusters are into one cluster.
Suppose we have following data points, and we have to separate them into different clusters-
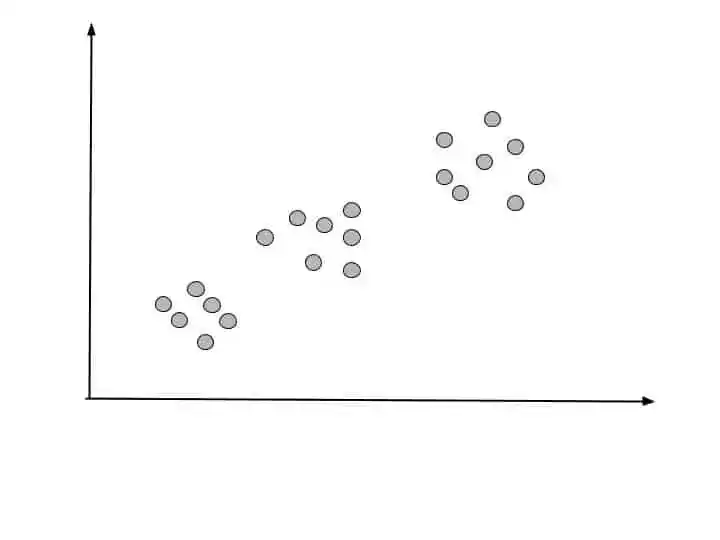
Hierarchical clustering cluster the data points based on its similarity. Hierarchical clustering continues clustering until one single cluster left.
As you can see in this image. Hierarchical clustering combines all three smaller clusters into one final cluster.
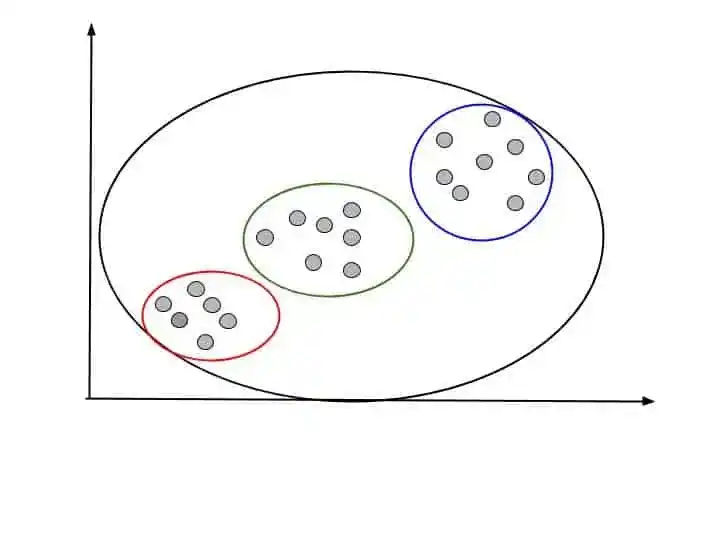
Before understanding how it works, first let’s see Hierarchical Clustering Types.
Type of Hierarchical Clustering
Hierarchical Clustering is of 2 types-
- Agglomerative Hierarchical Clustering.
- Divisive Hierarchical Clustering.
Let’s understand each type in detail-
1. Agglomerative Hierarchical Clustering.
Agglomerative Hierarchical Clustering uses a bottom-up approach to form clusters. That means it starts from single data points. Then it clusters the closer data points into one cluster. The same process repeats until it gets one single cluster.
Let’s understand with the help of an example-
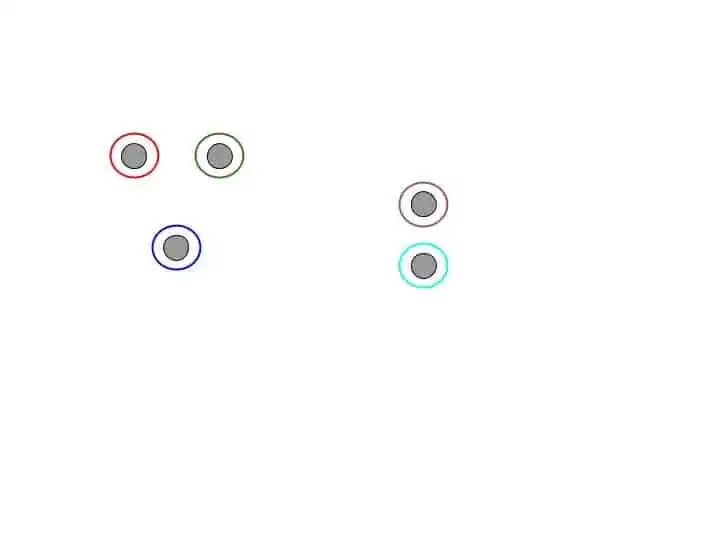
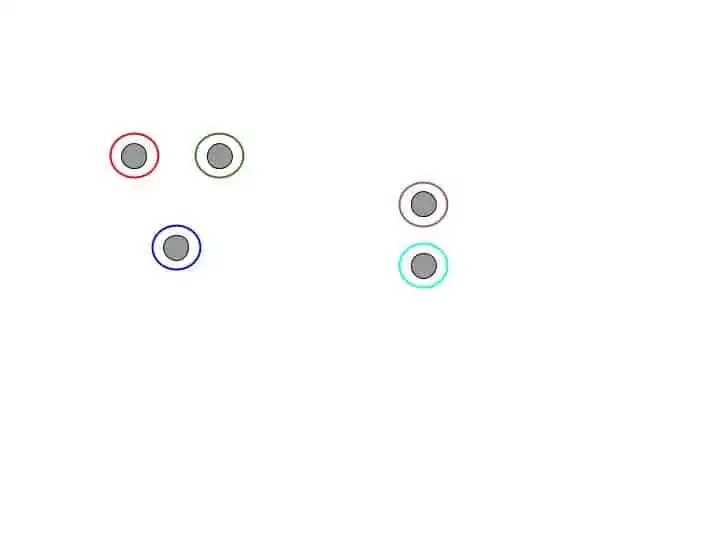
Suppose we have following data points.

So, agglomerative hierarchical clustering starts with each individual data points.
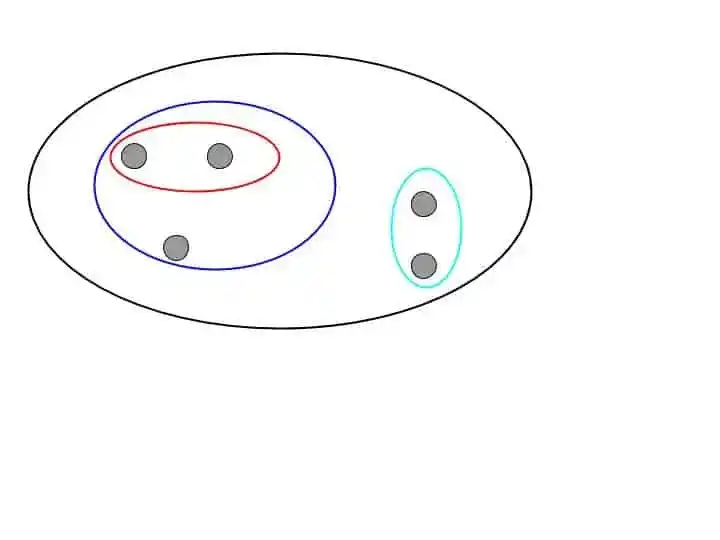
Then it clusters the closer data points into one cluster. This process continues until it forms a single cluster. That looks something like that-
2. Divisive Hierarchical Clustering.
Divisive Hierarchical Clustering is the opposite of Agglomerative Hierarchical clustering. It is a Top-Down approach.
That means, it starts from one single cluster. In that single cluster, there may be n number of clusters and data points.
At each step it split the farthest cluster into separate clusters.
Let’s understand with the help of this example-
Divisive Hierarchical Clustering start with this one single cluster-
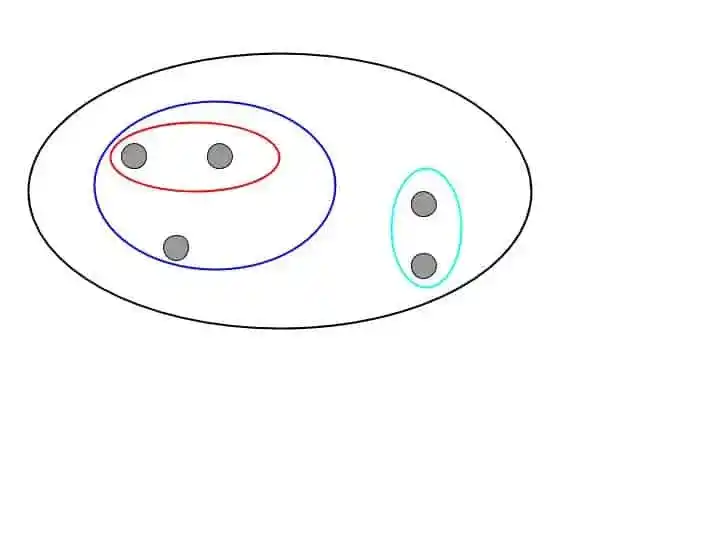
Then it split the furthest clusters into different clusters. This process continues until each data point has its own cluster. That looks something like that-
Divisive Hierarchical Clustering is not that much important than Agglomerative Hierarchical Clustering.
Agglomerative Hierarchical Clustering is used in many industries. That’s why, I will focus on Agglomerative Hierarchical Clustering in that article.
I hope now you understood What is Hierarchical Clustering and its types.
Now, let’s see How Hierarchical Clustering work.
NOTE- Whatever steps or procedure I will discuss for Hierarchical clustering is Agglomerative Hierarchical Clustering.
Steps to Perform Hierarchical Clustering.
I will discuss the whole working procedure of Hierarchical Clustering in Step by Step manner.
So, let’s see the first step-
Step 1- Make each data point a single cluster. Suppose that forms n clusters.
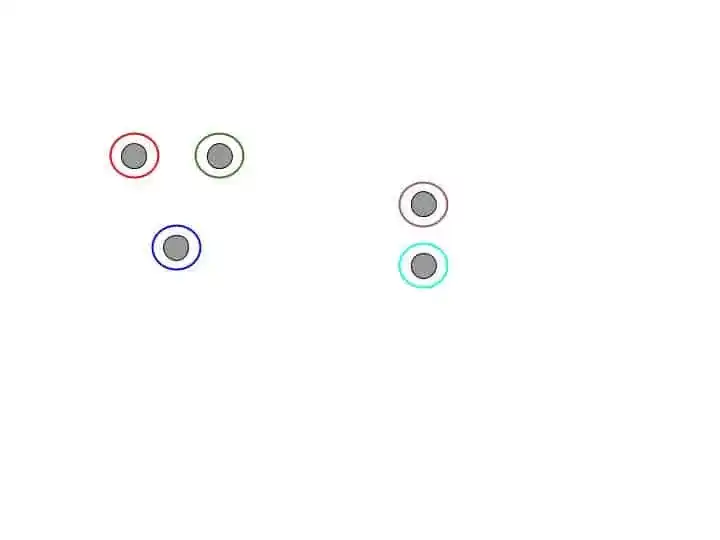
Step 2- Take the 2 closet data points and make them one cluster. Now the total clusters become n-1.
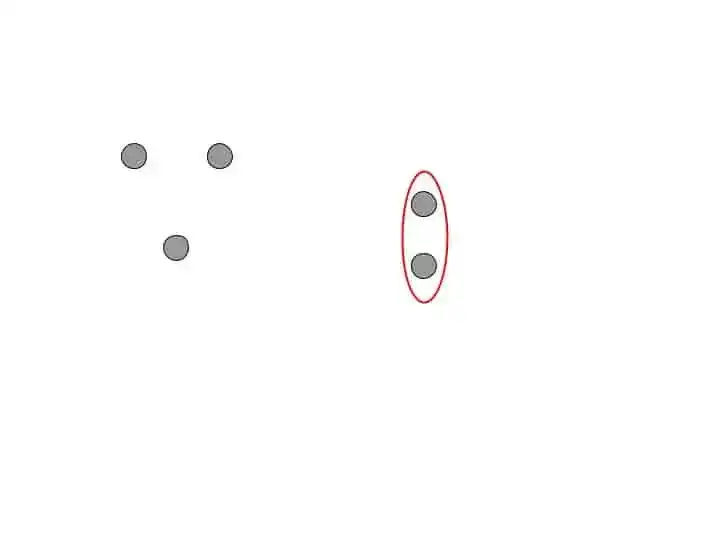
Step 3-Take the 2 closet clusters and make them one cluster. Now the total clusters become n-2.
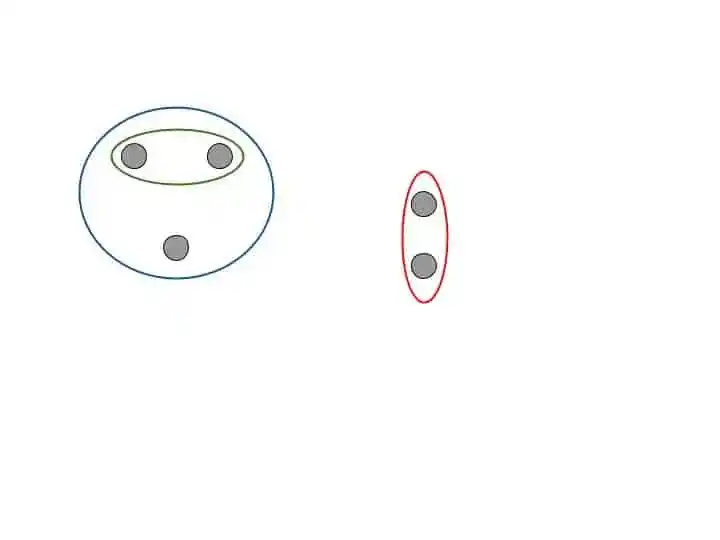
Step 4- Repeat Step 3 until only one cluster is left.
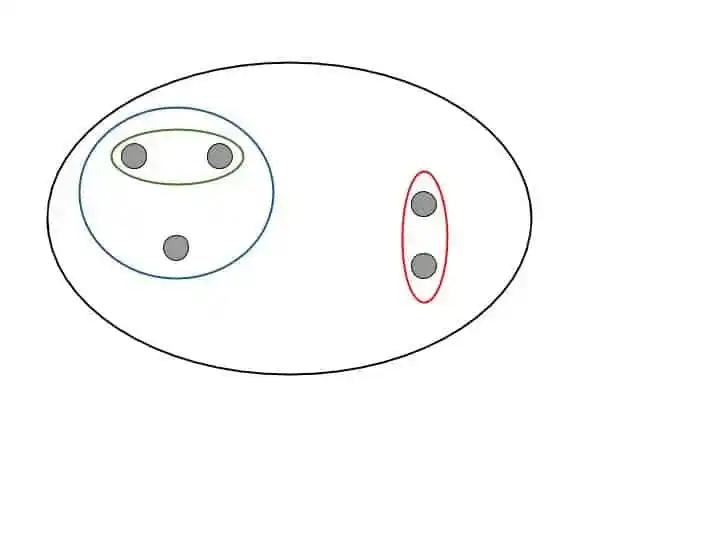
When only one huge cluster is left, the algorithms stops.
But, you may be wondering how to choose the closet clusters?. Because how to find the distance between two clusters is different than finding distance of two data points.
Right?.
So , let’s see.
How to calculate Distance between Two Clusters?
For calculating the distance between two data points, we use the Euclidean Distance Formula.
But, to calculate the distance between two clusters, we can use four methods-
1. Closet Points- That means we take the distance of two closet points from two clusters. It is also known as Single Linkage. Something like that-
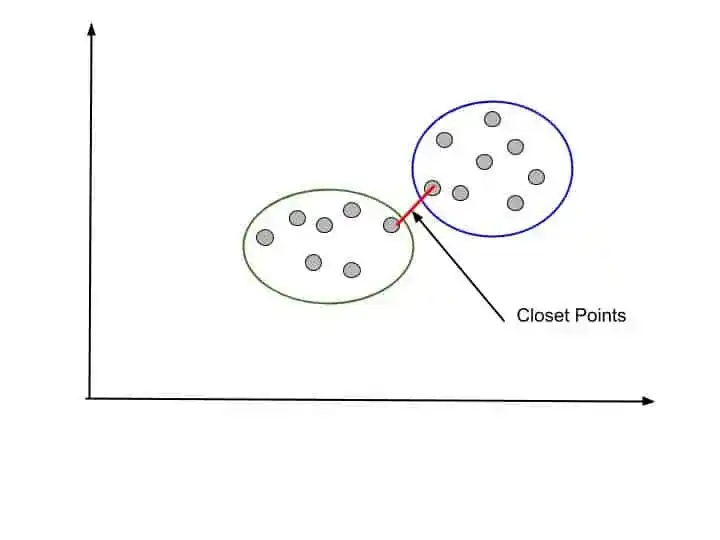
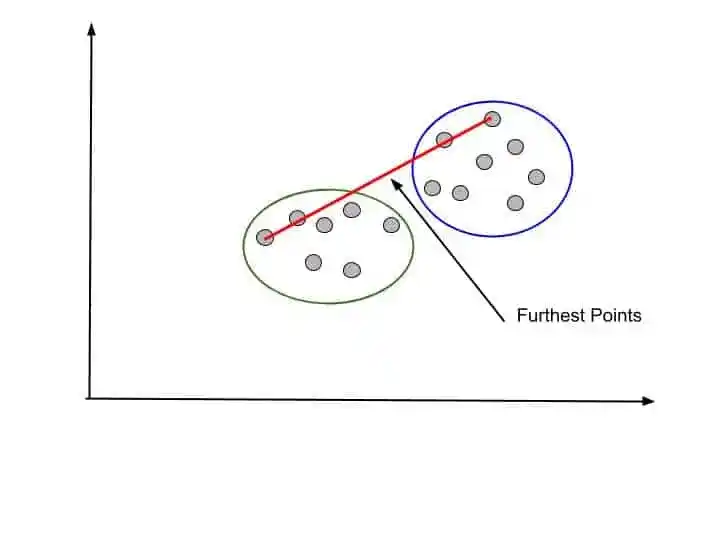
2. Furthest Points- Another option is to take the two furthest points and calculate their distance. And consider this distance as the distance of two clusters. It is also known as Complete-linkage
That look something like that-
3. Average Distance- In that method, you can take the average distance of all the data points and use this average distance as the distance of two clusters. It is known as Average-linkage.
4. Distance between Centroids- Another option is to find the centroid of clusters and then calculate the distance between two centroids. It is known as Centroid-linkage.
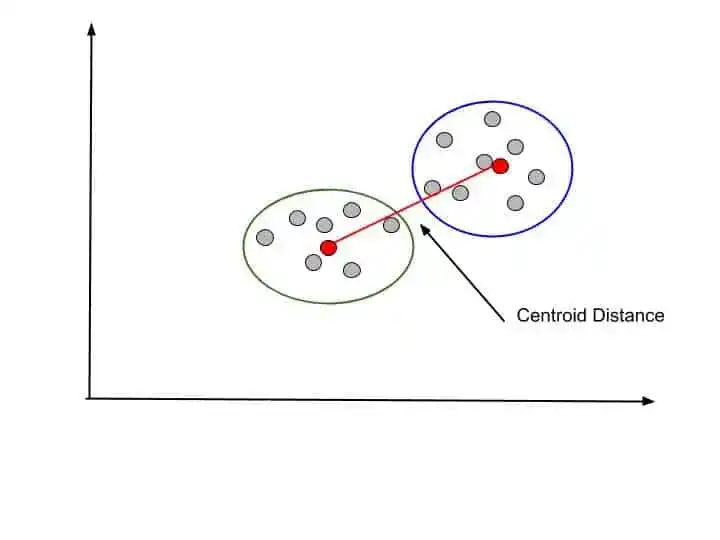
Choosing the method for distance calculation is an important part of Hierarchical Clustering. Because it affects performance.
That’s why you should keep in mind while working on Hierarchical clustering that distance between clusters are crucial.
Depending upon you problem you can choose the option.
Now you understood the steps to perform and Hierarchical Clustering.
The next question is How to Choose the optimal number of Clusters?
So, let’s see in the next section-
How to find Optimal Number of Clusters?
In K- Means Clustering algorithm, we use the Elbow Method to find the optimal number of Clusters. But in Hierarchical Clustering, we use Dendrogram.
What is Dendrogram?
A Dendrogram is a tree-like structure, that stores each record of splitting and merging.
Let’s understand how to create dendrogram and how it works-
How Dendrogram is Created?
Suppose, we have 6 data points.

A Dendrogram stores each record of splitting and merging in a chart.
Suppose this is our Dendrogram chart-
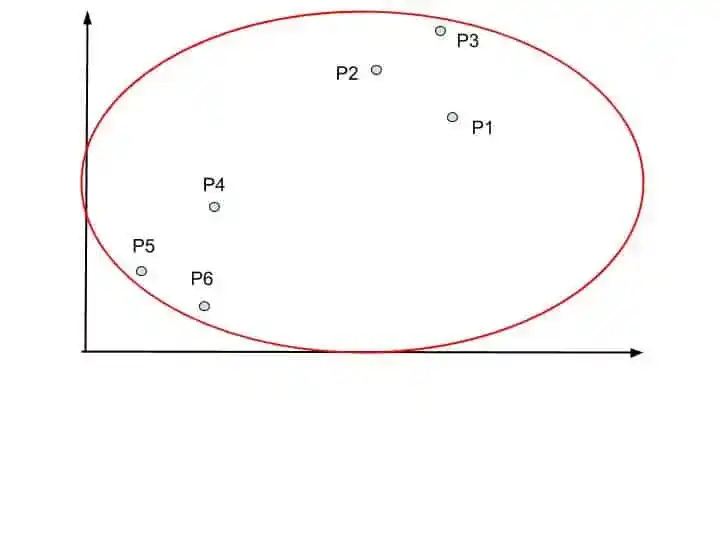
Here, all 6 data points P1, P2, P3, P4, P5, and P6 are mention.
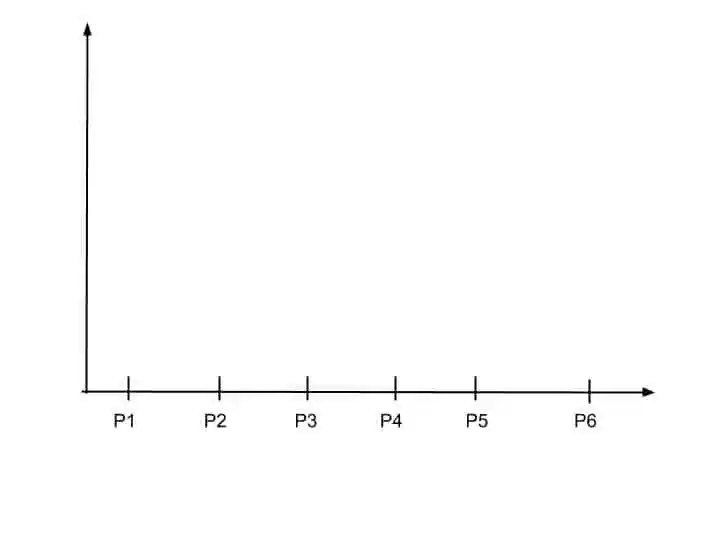
So, whenever any merging happen within data points and clusters, dendrogram update it on the chart.
So, let’s start with the 1st step.
Step 1
That is combine two closet data points into one cluster. Suppose these are two closet data points, so we combine them into one cluster.
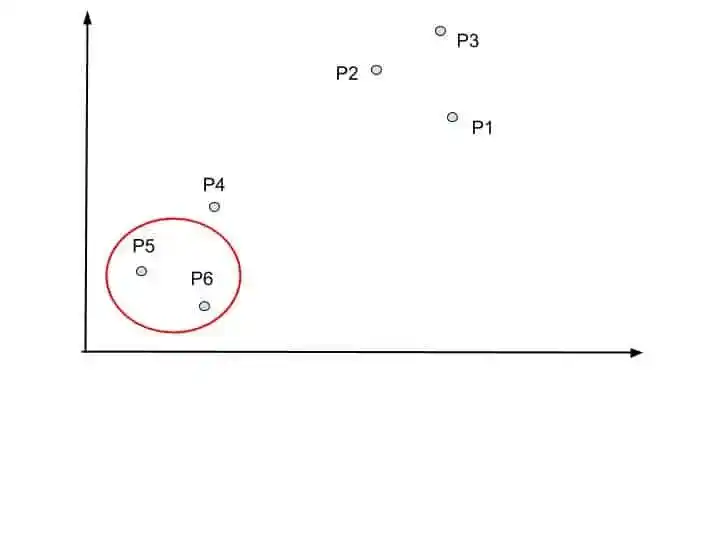
Here we combine P5 and P6 into one cluster. So Dendrogram update this merging into the chart.
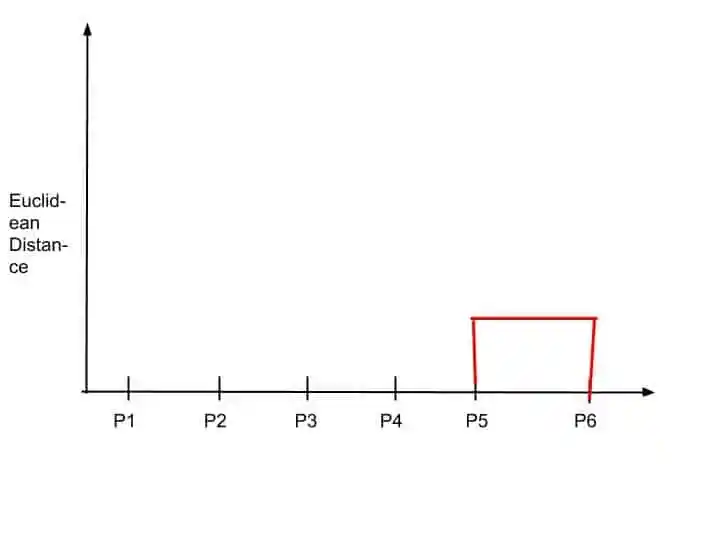
Dendrogram Store the records by drawing horizontal line in a chart. The height of this horizontal line is based on the Euclidean Distance.
The minimum the euclidean distance the minimum height of this horizontal line.
Step 2-
At step 2, find the next two closet data points and convert them into one cluster.
Suppose P2 and P3 are the next closet data points.
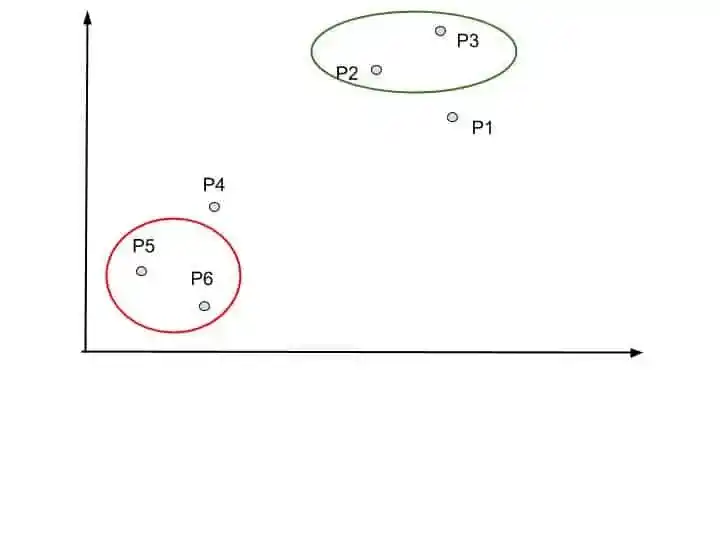
So, Dendrogram update this merging into the dendrogram chart.
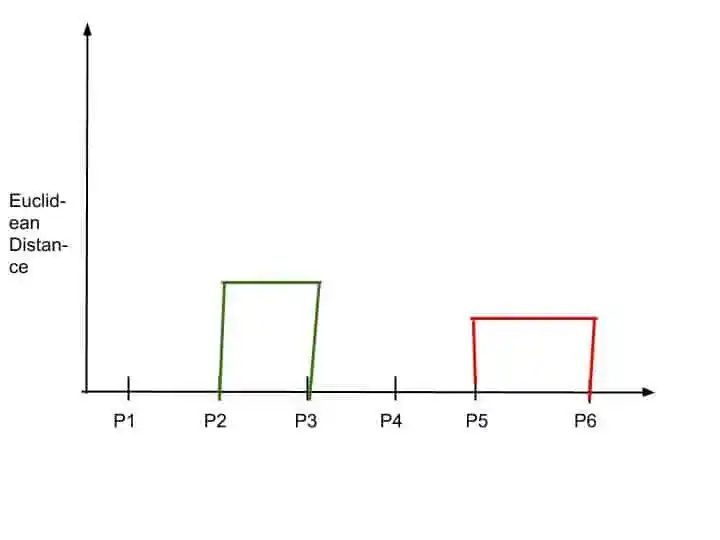
Again the height of this horizontal line depends upon the Euclidean Distance.
Step 3-
At step 3, again we look at the closet clusters. P4 is closer to the Red cluster.
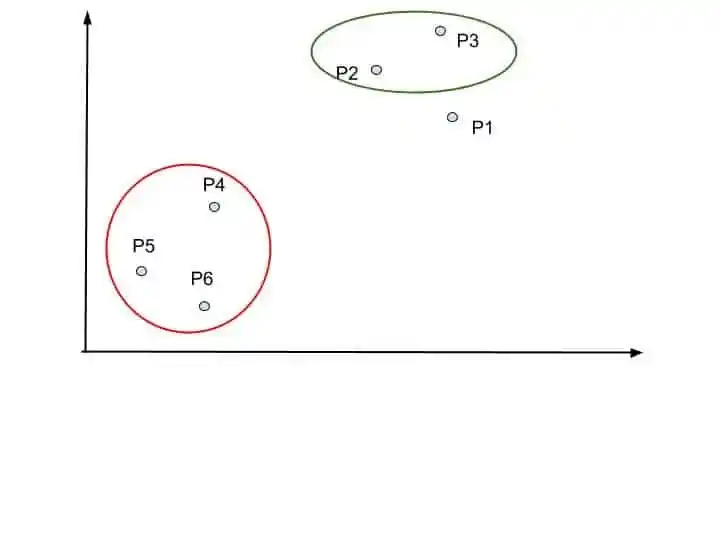
So, P4, P5, and P6 forms one cluster. The dendrogram update it into the dendrogram chart.
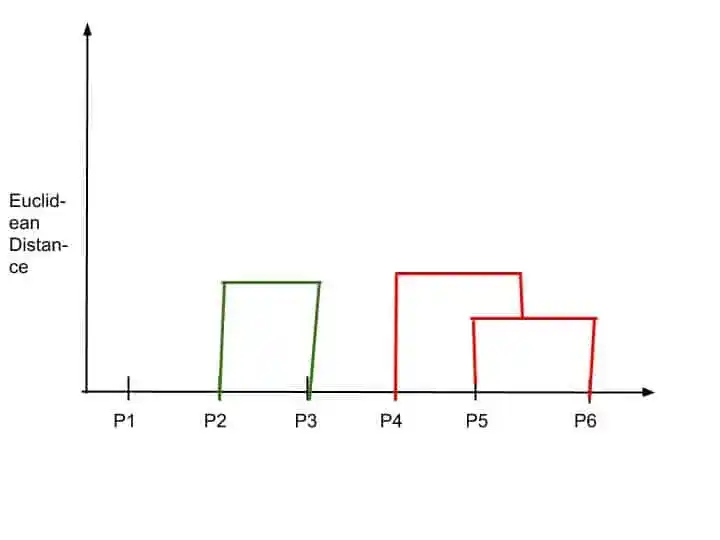
Step 4-
Again, we look at the closet clusters. P1 is closer to the green cluster. So merge the into one cluster.
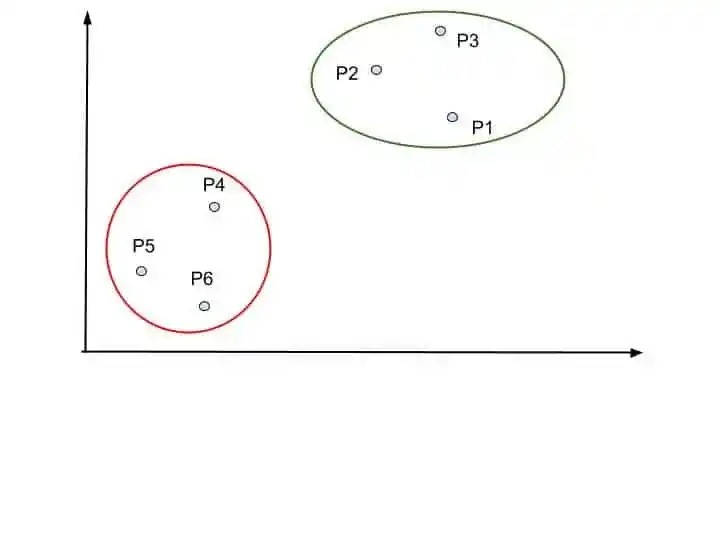
Dendrogram again update it into the chart.
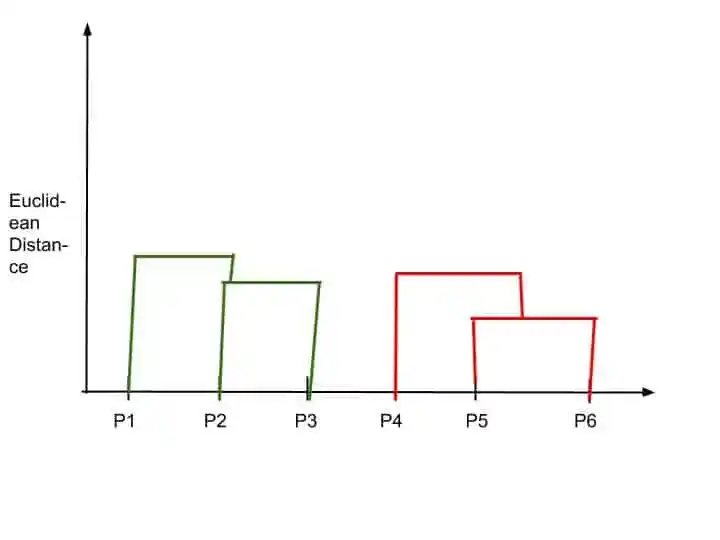
Step 5-
Now, no small clusters are left. So, the last step is to merge all clusters into one huge cluster.
Dendrogram draws the final horizontal line. The height of this line is big because the distance between cluster is very far.
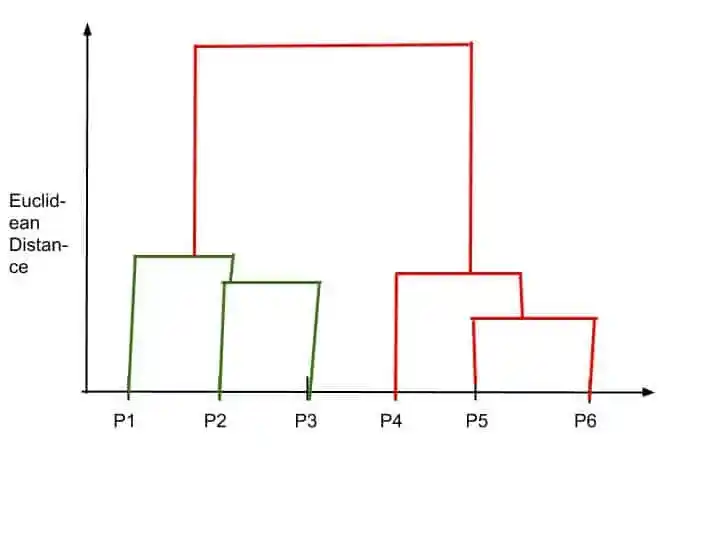
So, that’s how Dendrogram is created. I hope you understood. The dendrogram is the memory of Hierarchical clustering.
Now, we have created a Dendrogram, its time to find the optimal number of clusters with the help of Dendrogram.
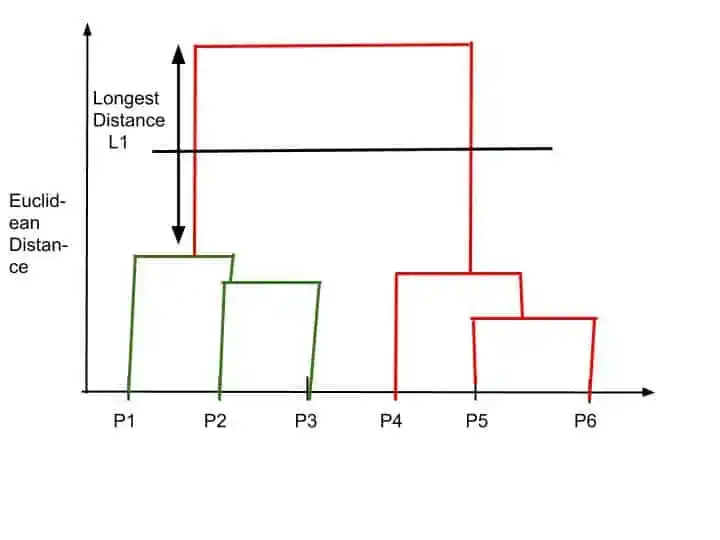
So, we can find the optimal number of cluster by cutting out dendrogram with a horizontal line. this horizontal line has highest distance and who can traverse the maximum distance up and down without intersecting the merging point.
Let’s understand with the help of this example-
Suppose in this dendrogram, this L1 is the longest distance, who can traverse maximum distance up and down without intersecting the merging points.
So, we make cut by drawing a horizontal line. That look something like that-
This cutting line intersects two vertical lines. And this is the optimal number of clusters.
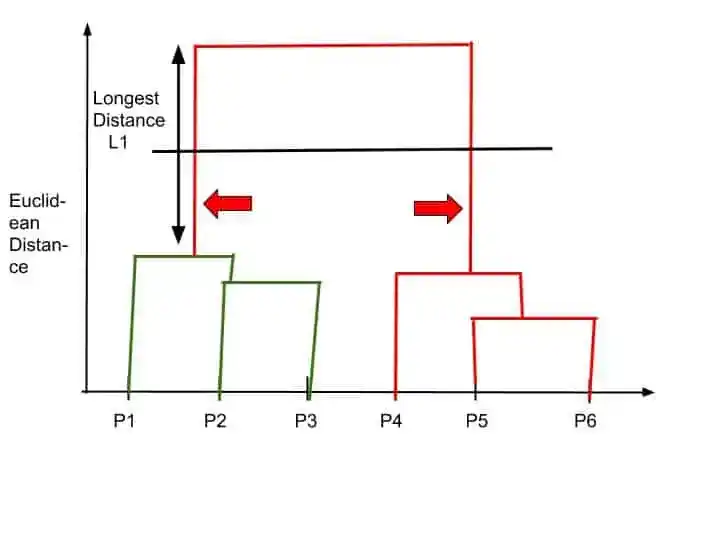
That’s why in that case, the optimal number of clusters are 2.
I hope you understood.
Now, its time to implement Hierarchical clustering into Python.
Implementation of Hierarchical Clustering into Python
Here I am using Mall Dataset, which contains all the details of Customers along with their spending score.
You can download the dataset from here.
So, the first step is-
Import the Libraries-
First import the three important library-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdAfter importing libraries, the next step is-
Load the Dataset-
dataset = pd.read_csv('Mall_Customers_dataset.csv')Dataset is loaded-
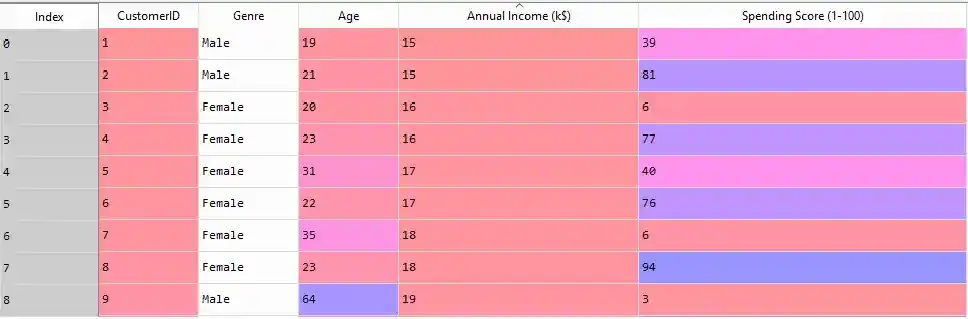
Our goal is to cluster the customers based on their Spending score. That’s why CustomerID and Genre are useless. So we remove both columns.
X = dataset.iloc[:, [3, 4]].valuesNow, we have only Annual Income and Spending Score Column.
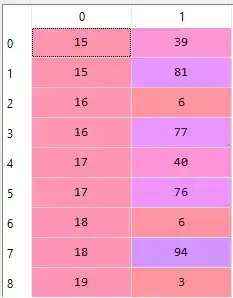
We have loaded dataset. Now its time to find the optimal number of clusters. And for that we need to create a Dendrogram.
Create Dendrogram to find the Optimal Number of Clusters
import scipy.cluster.hierarchy as sch
dendro = sch.dendrogram(sch.linkage(X, method = 'ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distances')
plt.show()
Here in the code “sch” is the short code for scipy.cluster.hierarchy.”
“dendro” is the variable name. It may be anything. And “Dendrogram” is the function name.
So, after implementing this code, we will get our Dendrogram.
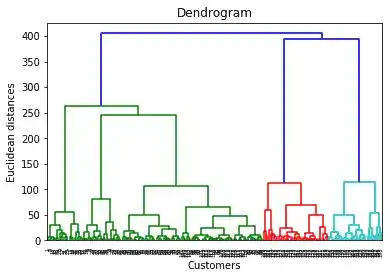
As I discussed that cut the horizontal line with longest line that traverses maximum distance up and down without intersecting the merging points.
In that dendrogram, the optimal number of clusters are 5.
Now let’s fit our Agglomerative model with 5 clusters.
Fitting Agglomerative Hierarchical Clustering to the dataset
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters = 5, affinity = 'euclidean', linkage = 'ward')
y_hc = hc.fit_predict(X)Now our model has been trained. If you want to see different clusters, you can do it by simply writing print.
print(y_hc)
Now, its time to visualize the clusters.
Visualise the clusters
plt.scatter(X[y_hc == 0, 0], X[y_hc == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X[y_hc == 1, 0], X[y_hc == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X[y_hc == 2, 0], X[y_hc == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X[y_hc == 3, 0], X[y_hc == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X[y_hc == 4, 0], X[y_hc == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()After implementing this code, we will get this interesting chart.
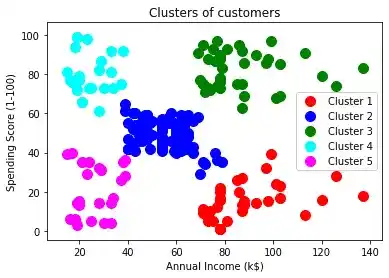
I hope, you understood the whole implementation of Hierarchical Clustering.
Now, its time to wrap up.
Conclusion
In this article, you learned everything related to the Hierarchical Clustering.
Specifically, you learned-
- What is the Clustering, Types of Clustering?
- What is Hierarchical Clustering?, Types of Hierarchical Clustering, and Steps to perform Hierarchical Clustering.
- What is Dendrogram, How to create Dendrogram?
- Hierarchical Clustering in Python.
I tried to make this article simple and easy for you. But still, if you have any doubt, feel free to ask me in the comment section. I will do my best to clear your doubt.
FAQ
Agglomerative Hierarchical Clustering and Divisive Hierarchical Clustering are the two types of Hierarchical Clustering.
Hierarchical Clustering can be used in Tracking Viruses through Phylogenetic Trees.
Hierarchical Clustering starts grouping clusters into one, whereas K Means Clustering separate the data points into K clusters.
Agglomerative Hierarchical clustering is called as bottom up approach.
* The algorithm can never undo any previous steps. Suppose if we cluster wrong data points, so we can’t undo that step.
* For large datasets, it is difficult to find the optimal number of clusters.
Learn the Basics of Machine Learning Here
Read K-Means Clustering here-K Means Clustering Algorithm: Complete Guide in Simple Words
Are you ML Beginner and confused, from where to start ML, then read my BLOG – How do I learn Machine Learning?
If you are looking for Machine Learning Algorithms, then read my Blog – Top 5 Machine Learning Algorithm.
If you are wondering about Machine Learning, read this Blog- What is Machine Learning?
Thank YOU!
Though of the Day…
‘ Anyone who stops learning is old, whether at twenty or eighty. Anyone who keeps learning stays young.
– Henry Ford

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.
