
Do you wanna know about K Fold Cross-Validation?. If yes, then this blog is just for you. Here I will discuss What is K Fold Cross-Validation?, how K Fold works, and all other details.?. So, give your few minutes to this article in order to get all the details regarding K Fold Cross-Validation.
Hello, & Welcome!
In this blog, I am gonna tell you-
K Fold Cross-Validation
K Fold Cross Validation is used to solve the problem of Train-Test Split.
Now you have question, What is Train-Test Split?.
Right?.
So, in order to understand K Fold cross-validation, first, understand Train-Test Split problem.
What is Train-Test Split Problem?
Train-Test split is nothing but splitting your data into two parts. Traning Data and Test Data.
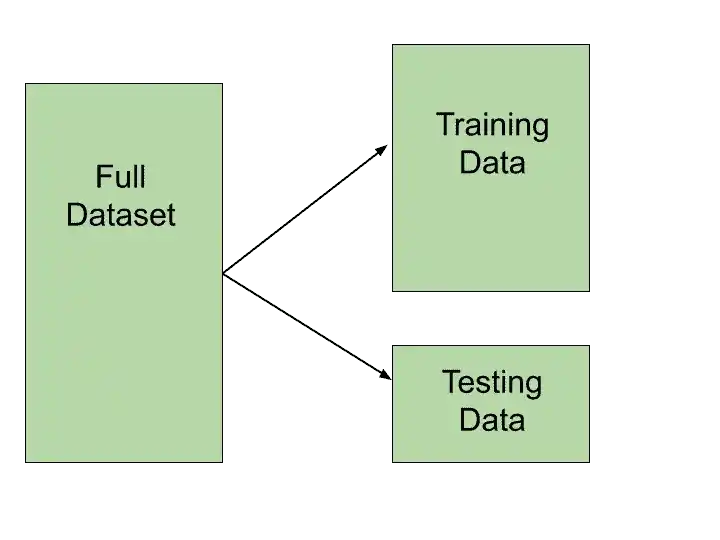
Training Data is data that is used to train the model.
Test Data is used to test the performance of the model after the training phase.
So, the question comes here is how to split your data into two parts?. Or at what proportion, we should split our data?.
Suppose we have 1000 records in our data. So we can split data into 70% and 30% or 75% or 25% data. That means we require 70% data for training and 30% data for testing. It depends upon the number of data records.
So, we train our model with 70% data. And after Training, we test our model performance with 30% data. And check the accuracy.
Accuracy maybe 80%, 85%, and anything else.
The Data we have selected for training and testing is randomly selected.
Due to random selection, some kind of data that is present in Test data may not present in Training data. So what will happen?.
The accuracy will decrease.
So, whenever we perform Train-Test split, we use a random_state variable. And then we define the value of random_state.
And based on this random_state variable, data is selected randomly.
So What’s the problem here?.
Suppose, first we have chosen random_state =5. And Split the data in 70% and 30%. So the accuracy we got is around 80%.
But, again when we choose random_state=10. And Train-Test split at 70% and 30%. So the Training data and Testing Data gets shuffled. That means the data which we had in the previous round, is now shuffled. Now we have different data in Training Data and in Testing Data.
And now we got an accuracy of 85%.
So, the problem is our accuracy fluctuates with different random_state. And we can’t say that what accuracy our model has.
Therefore to prevent this problem, Cross-Validation is used.
Now, let’s see What is Cross-Validation?. and how does it work?.
What is Cross-Validation?
To evaluate the performance of a model, we use Cross-Validation.
Cross-Validation split the dataset into different segments. And use each segment for training as well as testing one by one.
You can understand with the help of this image-
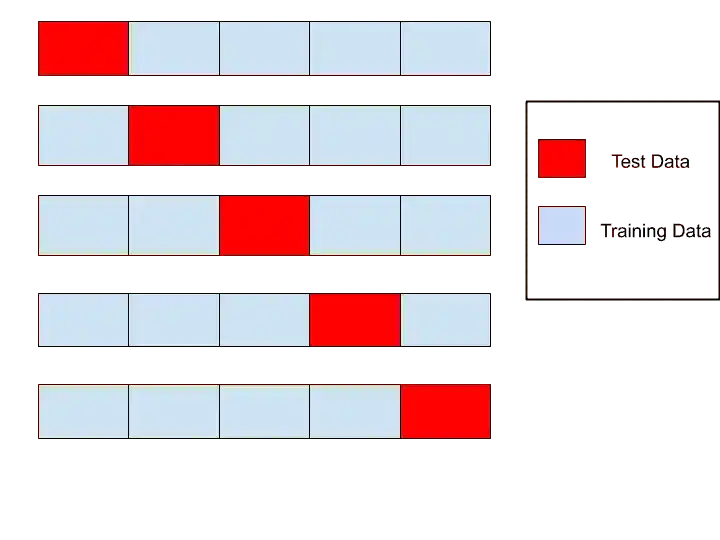
Cross-Validation has various types. Let’s understand the different types of Cross-Validation.
Types of Cross-Validation
Cross-Validation has following types-
- Leave One Out Cross-Validation
- K-Fold Cross-Validation.
- Stratified Cross-Validation.
- Time-Series Cross-Validation
Let’s start with Leave One Out Cross-Validation.
1. Leave One Out Cross-Validation (LOOCV)
So, How Leave One Out Cross-Validation works?
Let’s see.
Suppose, we have 500 records in our dataset. So what Leave One Out Cross-validation does?. It basically takes one record for the Test dataset and the remaining record for the Training dataset.
Let’s understand with the help of an example-
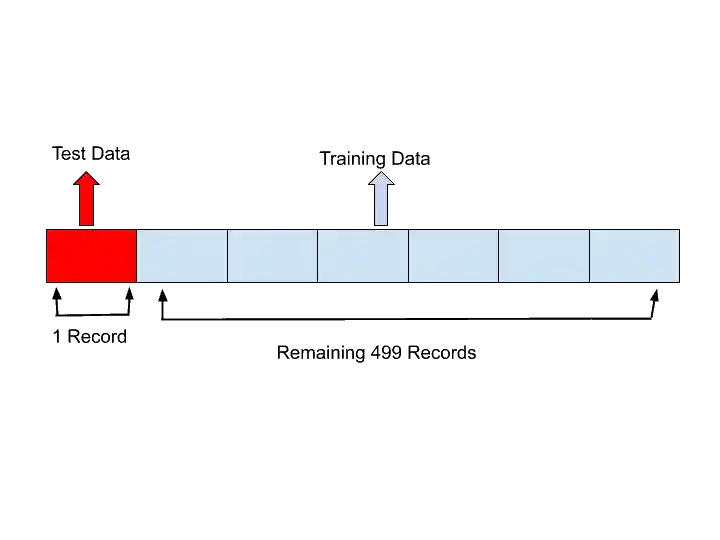
So, here Leave One Out method have chosen one record for test data, and the remaining 499 records for Training data. Here Leave One Out method train the model with 499 records. And test the model performance with a single record. This is round 1.
In the second round, it will choose the second record for test data and the remaining 499 records for training data.
Something like that…
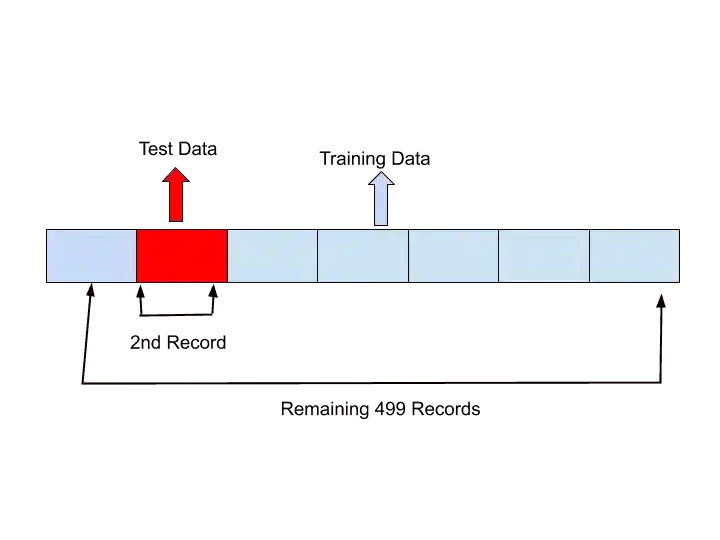
Similarly, it will take the next one record for testing, and the remaining 499 records for Training.
As its name suggests, “Leave One Out”, therefore it leave only one record for testing.
So, the problem with Leave One Out method is that it is a time-consuming process. Suppose we have 10000 records in our dataset. Then we have to perform 10000 iterations for every single record. And that is a very time-consuming process.
The disadvantage of Leave One Out Cross-Validation
Leave One Out method has the following disadvantages,
- We need to perform many iterations depending upon the number of records.
- Leave One Out lead to low bias.
Now, Let’s move into the next type of Cross-Validation. And that is K fold Cross-Validation.
2. What is K Fold CV?
K Fold Cross-Validation is very simple. And easy to understand.
So what K Fold Cross-Validation does?.
K fold cross-validation solves the problem of the Train-Test split.
How K Fold Cross-Validation solves the problem of Train-Test split?
K Fold selects the k value, and based on this k value, we split the data.
Let me simplify it,
Suppose we have 1000 records in our dataset. And we select the value of K as 5. So K value means, the number of rounds we perform Training and Testing.
And here, our k value is 5, that means we have to perform 5 round of Training and Testing.

For each experiment, based on the K value, it will decide the number of Test Data.
Here, our k value is 5. And we have 1000 records.
Right?.
So when we divide 1000 with 5.
1000/5=200
So, 200 will be our Test Data. And the remaining 800 records will be our Training Data.
So for the first round, the first 200 records are used for Test Data and the remaining 800 for Training data.

This is the first round. So, this model is trained with 800 datasets. And tested on 200 datasets. After that, we got our first Accuracy. Let’s say Accuracy 1.
Now, What will happen in the second round?
In second round, the next 200 records will be our Test data, and the remaining 800 data is our Training data.
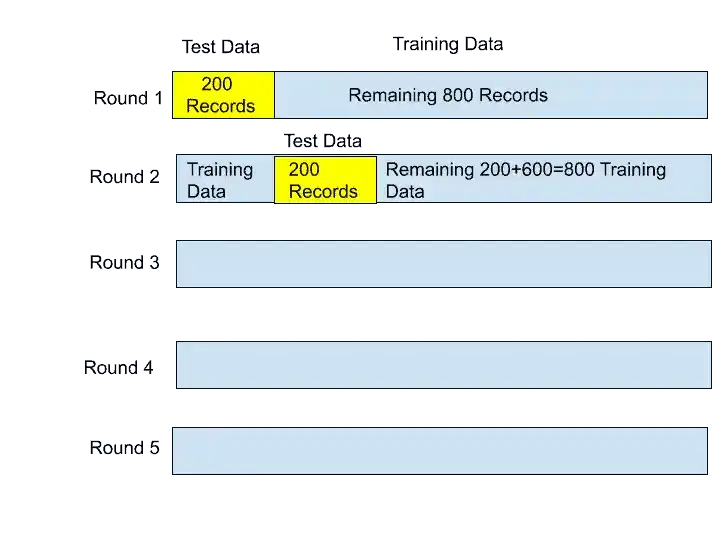
Here, our model is trained on 800 records and tested on the next 200 records. And Again we got some accuracy. Let’s say Accuracy 2.
In the same way, all rounds happened., and we got accuracies with each round.
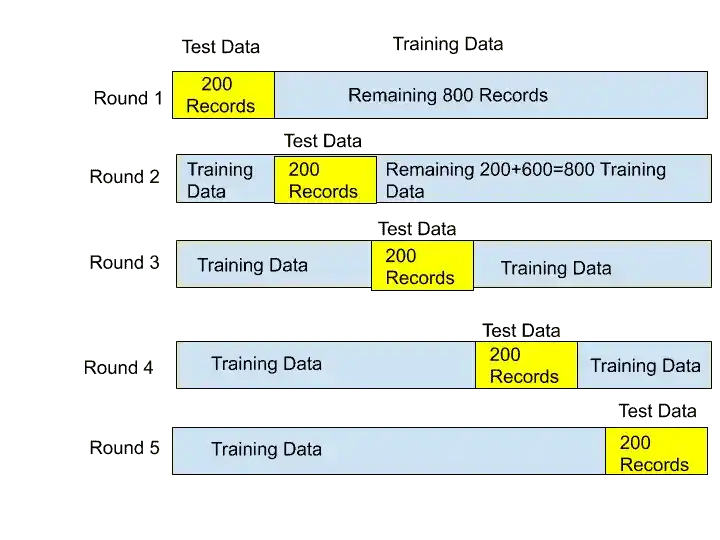
So after completing all 5 rounds, we got 5 accuracies. The Accuracy 1, Accuracy 2, Accuracy 3, Accuracy 4, and accuracy 5.
So, What can we do with these Accuracies?
We can take all Accuracies, and find out the Mean. And that Mean of all 5 accuracies is the actual accuracy of your model.
By doing so, your accuracy will not fluctuate as in Train-Test Split. Moreover, you will get your model minimum accuracy and maximum accuracy.
Now, you have a question in your mind, How to Choose the value of K?
Now, Let’s see
How to Choose the K value?
The value of k should be chosen carefully. If you choose poor k value, it will result in high variance or high bias.
The value of K depends upon the size of the data. Along with that, How much your system is capable to afford the computational cost. The high K value, the more rounds or folds you need to perform.
So, before selecting the K value, look at your data size and your system computation power.
There are some common strategies for choosing the k value-
k=10-> This is the value found by after various experiments. k=10 will result in a model with low bias and moderate variance. So if you are struggling to choose the value of k for your dataset, you can choose k=10. The value of k as 10 is very common in the field of machine learning.
K=n-> The value of k is n, where n is the size of the dataset. That means using each record in a dataset to test the model. That is nothing but Leave One Out Approach.
There is no formal rule but the value of k should be 5 or 10.
I hope, now you understood.
Now, let’s see some disadvantages of K Fold Cross-Validation.
Disadvantages of K Fold Cross-Validation
Suppose in Round 1, we have 200 Test Dataset. But what if all these test datasets are of the same type?.
That means, suppose we are working on classification problem, and we have dataset only in binary form, like 0 and 1.
And we have only 0’s in the test dataset. So, this is an Imbalanced dataset. And that can be a problem. In that case, you will not get accurate results.
In order to solve this problem, Stratified Cross-Validation is used.
3. Stratified Cross-Validation
In Stratified Cross-validation, everything will be the same as in K fold Cross-Validation. But in Stratified Cross-Validation, whenever the Test Data is selected, make sure that the number of instances of each class for each round in train and test data, is taken in a proper way.
Confused?.
No worry!.
Let me simplify it.
Suppose we have 500 records, in which we have 400 Yes, and 100 Now. And that is Imbalanced Dataset.
So in that case, What Stratified Cross-Validation will do?.
It will make sure that in Training Dataset, there should be a proper proportion of Yes and No. And also In the Test dataset, there should be a proper proportion of Yes and No.
By doing so, our model will give an accurate result.
I hope now you understood What Stratified Cross-Validation does?.
Now let’s move into the next type of Cross-Validation.
4. Time-Series Cross-Validation
Time Series Cross-Validation works for a completely different problem.
So, Where Time Series Cross-Validation will work?
When you have a dataset related to time series. Like Stock Price Prediction. In Stock Price Prediction, we have to predict future data.
So, in Stock Price Prediction data, we can’t perform Train-Test Split. Because this data is time-series data.
Suppose we have 4 days Data. And we have to predict the stock price for Day 5 and Day 6.
For that, we are dependent upon data of 4 days.
Based on Day1, Day2, Day3, and Day4 data, we can predict the stock price of Day 5 Data.
Right?.
Similarly, for Day 6, we use Day 2, Day 3, Day 4, and Day 5 data for predicting stock price for Day 6.
Understand with the help of this image.
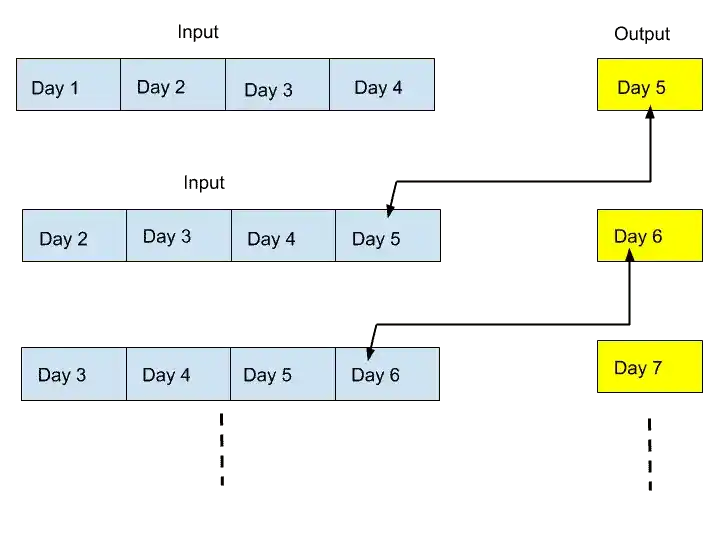
So, that’s how Time Series Cross-Validation works. It will use the previous day data to predict the stock price for next day data.
I hope now, you understood how it works.
Conclusion
In that article, you understood everything related to K Fold Cross-Validation.
In that article, you learned the following concepts-
- Why K fold Cross-Validation is used?
- What is Train Test Split Problem?.
- Types of Cross-Validation.
- Leave One Out Cross-Validation.
- What is K Fold Cross-Validation?, How to Choose k Value?, Disadvantages of K Fold.
- Stratified Cross-Validation.
- Time Series Cross-Validation.
I hope, you understood each and every topic easily.
If you have any doubt, feel free to ask me in the comment section.
FAQ
Enjoy Machine Learning
All the Best!
Learn the Basics of Machine Learning Here
Are you ML Beginner and confused, from where to start ML, then read my BLOG – How do I learn Machine Learning?
If you are looking for Machine Learning Algorithms, then read my Blog – Top 5 Machine Learning Algorithm.
If you are wondering about Machine Learning, read this Blog- What is Machine Learning?
Thank YOU!
Though of the Day…
‘ Anyone who stops learning is old, whether at twenty or eighty. Anyone who keeps learning stays young.
– Henry Ford

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.